本文内容如下:
- 结构概述
- 用来构建卷积神经网络的各种层
- 卷积层
- 汇聚层
- 归一化层
- 全连接层
- 将全连接层转化成卷积层
- 卷积神经网络的结构
- 层的排列规律
- 层的尺寸设置规律
- 案例学习(LeNet / AlexNet / ZFNet / GoogLeNet / VGGNet)
- 计算上的考量
- 拓展资源
卷积神经网络(CNNs / ConvNets)
卷积神经网络是由神经元组成,神经元中有具有学习能力的权重和偏差。每个神经元都得到一些输入数据,进行内积运算后再进行激活函数运算。整个网络依旧是一个可导的评分函数:该函数的输入是原始的图像像素,输出是不同类别的评分。在最后一层(往往是全连接层),网络依旧有一个损失函数(比如SVM或Softmax),并且在神经网络中我们实现的各种技巧和要点依旧适用于卷积神经网络。
那么有哪些地方变化了呢?卷积神经网络的结构基于一个假设,即输入数据是图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。
结构概述
我们前面讲过的神经网络结构都比较一致,输入层和输出层中间夹着数层隐藏层,每一层都由多个神经元组成,层和层之间是全连接的结构,同一层的神经元之间没有连接。
卷积神经网络是上述结构的一种特殊化处理,因为对于图像这种数据而言,上面这种结构实际应用起来有较大的困难:就拿CIFAR-10举例吧,图片已经很小了,是32323(长宽各32像素,3个颜色通道)的,那么在神经网络当中,我们只看隐藏层中的一个神经元,就应该有32323=3072个权重,如果大家觉得这个权重个数的量还行的话,再设想一下,当这是一个包含多个神经元的多层神经网(假设n个),再比如图像的质量好一点(比如是2002003的),那将有2002003*n= 120000n个权重需要训练,结果是拉着这么多参数训练,基本跑不动,跑得起来也是『气喘吁吁』,当然,最关键的是这么多参数的情况下,分分钟模型就过拟合了。别急,别急,一会儿我们会提到卷积神经网络的想法和简化之处。
卷积神经网络结构比较固定的原因之一,是图片数据本身的合理结构,类图像结构(2002003),我们也把卷积神经网络的神经元排布成 widthheightdepth的结构,也就是说这一层总共有widthheightdepth个神经元(这里的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数),如下图所示。举个例子说,CIFAR-10中的图像是作为卷积神经网络的输入,该数据体的维度是32x32x3(宽度,高度和深度),CIFAR-10的输出层就是1110维的。另外我们后面会说到,每一层的神经元,其实只和上一层里某些小区域进行连接,而不是和上一层每个神经元全连接。
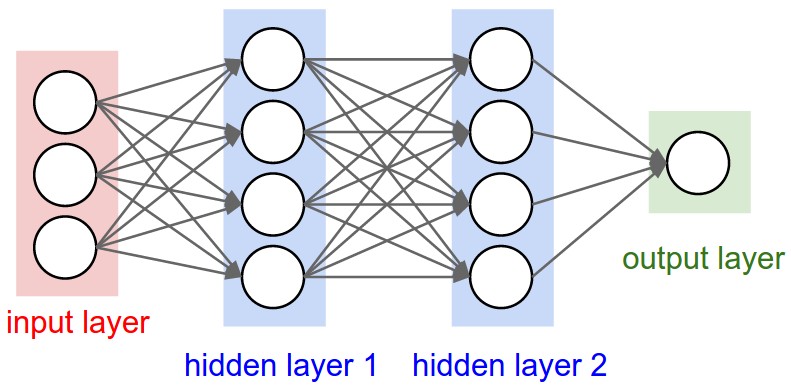
卷积神经网络的组成层
在卷积神经网络中,有3种最主要的层,一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可以微分的函数将激活数据从一个层传递到另一个层。
- 卷积运算层
- 汇聚(pooling)层
- 全连接层
一个完整的神经网络就是由这三种层叠加组成的。
网络结构例子:这仅仅是个概述,下面会更详解的介绍细节。一个用于CIFAR-10图像数据分类的卷积神经网络的结构可以是[输入层-卷积层-ReLU层-汇聚层-全连接层]。细节如下:
- 输入[32x32x3]存有图像的原始像素值,本例中图像宽高均为32,有3个颜色通道。
- 卷积层中,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。卷积层会计算所有神经元的输出。如果我们使用12个滤波器(也叫作核),得到的输出数据体的维度就是[32x32x12]。
- ReLU层将会逐个元素地进行激活函数操作,比如使用以0为阈值的max(0,x)作为激活函数。该层对数据尺寸没有改变,还是[32x32x12]。
- 汇聚层在在空间维度(宽度和高度)上进行降采样(downsampling)操作,数据尺寸变为[16x16x12]。
- 全连接层将会计算分类评分,数据尺寸变为[1x1x10],其中10个数字对应的就是CIFAR-10中10个类别的分类评分值。正如其名,全连接层与常规神经网络一样,其中每个神经元都与前一层中所有神经元相连接。
由此看来,卷积神经网络一层一层地将图像从原始像素值变换成最终的分类评分值。其中有的层含有参数,有的没有。具体说来,卷积层和全连接层(CONV/FC)对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数(神经元的突触权值和偏差)。而ReLU层和汇聚层则是进行一个固定不变的函数操作。卷积层和全连接层中的参数会随着梯度下降被训练,这样卷积神经网络计算出的分类评分就能和训练集中的每个图像的标签吻合了。
小结:
- 简单案例中卷积神经网络的结构,就是一系列的层将输入数据变换为输出数据(比如分类评分)。
- 卷积神经网络结构中有几种不同类型的层(目前最流行的有卷积层、全连接层、ReLU层和汇聚层)。
- 每个层的输入是3D数据,然后使用一个可导的函数将其变换为3D的输出数据。
- 有的层有参数,有的没有(卷积层和全连接层有,ReLU层和汇聚层没有)。
- 有的层有额外的超参数,有的没有(卷积层、全连接层和汇聚层有,ReLU层没有)。
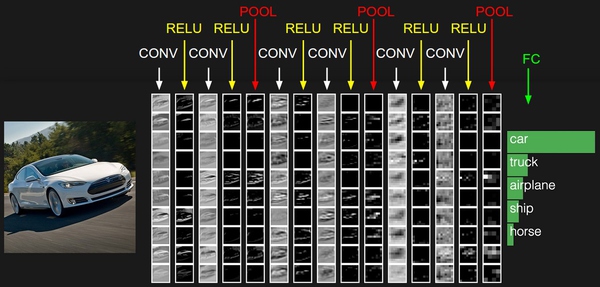
卷积层
卷积层是构建卷积神经网络的核心层,它产生了网络中大部分的计算量
卷积层综述
直观看来,卷积层的参数其实可以看做,一系列的可训练/学习的过滤器。在前向计算过程中,我们输入一定区域大小(width*height)的数据,和过滤器点乘后等到新的二维数据,然后滑过一个个滤波器,组成新的3维输出数据。而我们可以理解成每个过滤器都只关心过滤数据小平面内的部分特征,当出现它学习到的特征的时候,就会呈现激活/activate态。
局部关联度。这是卷积神经网络的独特之处其中之一,我们知道在高维数据(比如图片)中,用全连接的神经网络,实际工程中基本是不可行的。卷积神经网络中每一层的神经元只会和上一层的一些局部区域相连,这就是所谓的局部连接性。你可以想象成,上一层的数据区,有一个滑动的窗口,只有这个窗口内的数据会和下一层神经元有关联,当然,这个做法就要求我们手动敲定一个超参数:窗口大小。通常情况下,这个窗口的长和宽是相等的,我们把长x宽叫做receptive field。实际的计算中,这个窗口是会『滑动』的,会近似覆盖图片的所有小区域。
举个实例,CIFAR-10中的图片输入数据为[32323]的,如果我们把receptive field设为55,那receptive field的data都会和下一层的神经元关联,所以共有55*3=75个权重,注意到最后的3依旧代表着RGB 3个颜色通道。
如果不是输入数据层,中间层的data格式可能是[161620]的,假如我们取33的receptive field,那单个神经元的权重为33*20=180。
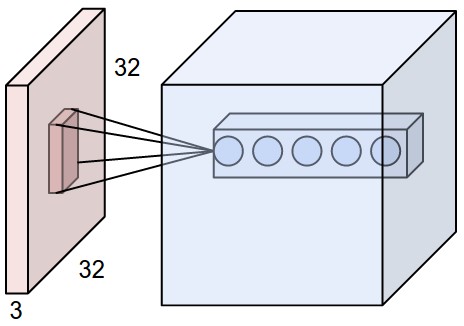 局部关联细节。我们刚才说到卷积层的局部关联问题,这个地方有一个receptive field,也就是我们直观理解上的『滑动数据窗口』。从输入的数据到输出数据,有三个超参数会决定输出数据的维度,分别是深度/depth,步长/stride 和 填充值/zero-padding:
局部关联细节。我们刚才说到卷积层的局部关联问题,这个地方有一个receptive field,也就是我们直观理解上的『滑动数据窗口』。从输入的数据到输出数据,有三个超参数会决定输出数据的维度,分别是深度/depth,步长/stride 和 填充值/zero-padding:
- 所谓深度/depth,简单说来指的就是卷积层中和上一层同一个输入区域连接的神经元个数,它和使用的滤波器的数量一致,而每个滤波器在输入数据中寻找一些不同的东西。。这部分神经元会在遇到输入中的不同feature时呈现activate状态,举个例子,如果这是第一个卷积层,那输入到它的数据实际上是像素值,不同的神经元可能对图像的边缘。轮廓或者颜色会敏感。
- 所谓步长/stride,是指的窗口从当前位置到下一个位置,『跳过』的中间数据个数。比如从图像数据层输入到卷积层的情况下,也许窗口初始位置在第1个像素,第二个位置在第5个像素,那么stride=5-1=4.
- 所谓zero-padding是在原始数据的周边补上0值的圈数。(下面第2张图中的样子)
这么解释可能理解起来还是会有困难,我们找两张图来对应一下这三个量:
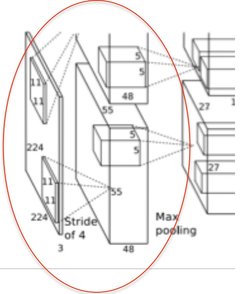 这是解决ImageNet分类问题用到的卷积神经网络的一部分,我们看到卷积层直接和最前面的图像层连接。图像层的维度为[2272273],而receptive field设为1111,图上未标明,但是滑动窗口的步长stride设为4,深度depth为48+48=96(这是双GPU并行设置),边缘没有补0,因此zero-padding为0,因此窗口滑完一行,总共停留次数为(data_len-receptive_field_len+2zero-padding)/stride+1=(227-11+20)/4+1=55,因为图像的长宽相等,因此纵向窗口数也是55,最后得到的输出数据维度为5555*96维。
这是解决ImageNet分类问题用到的卷积神经网络的一部分,我们看到卷积层直接和最前面的图像层连接。图像层的维度为[2272273],而receptive field设为1111,图上未标明,但是滑动窗口的步长stride设为4,深度depth为48+48=96(这是双GPU并行设置),边缘没有补0,因此zero-padding为0,因此窗口滑完一行,总共停留次数为(data_len-receptive_field_len+2zero-padding)/stride+1=(227-11+20)/4+1=55,因为图像的长宽相等,因此纵向窗口数也是55,最后得到的输出数据维度为5555*96维。
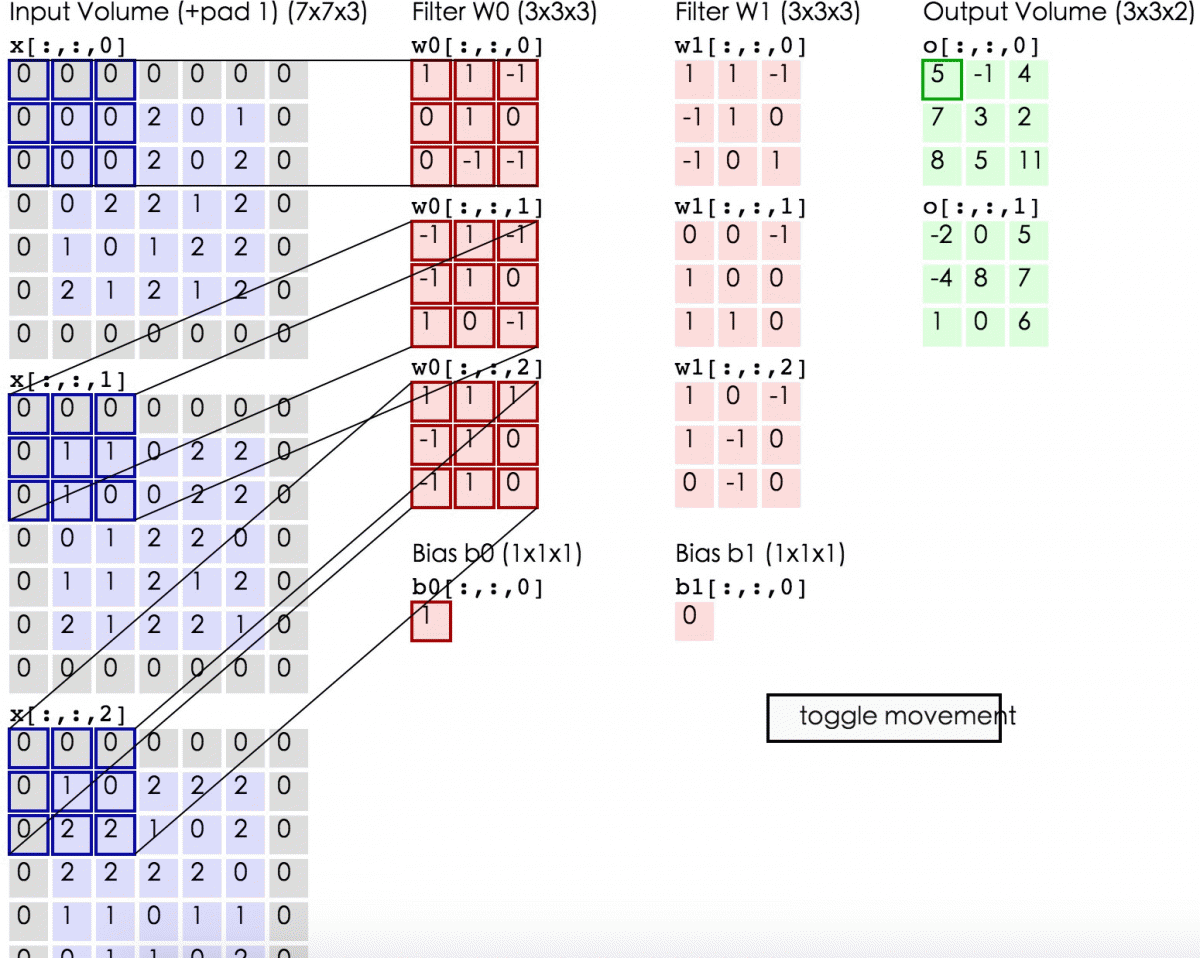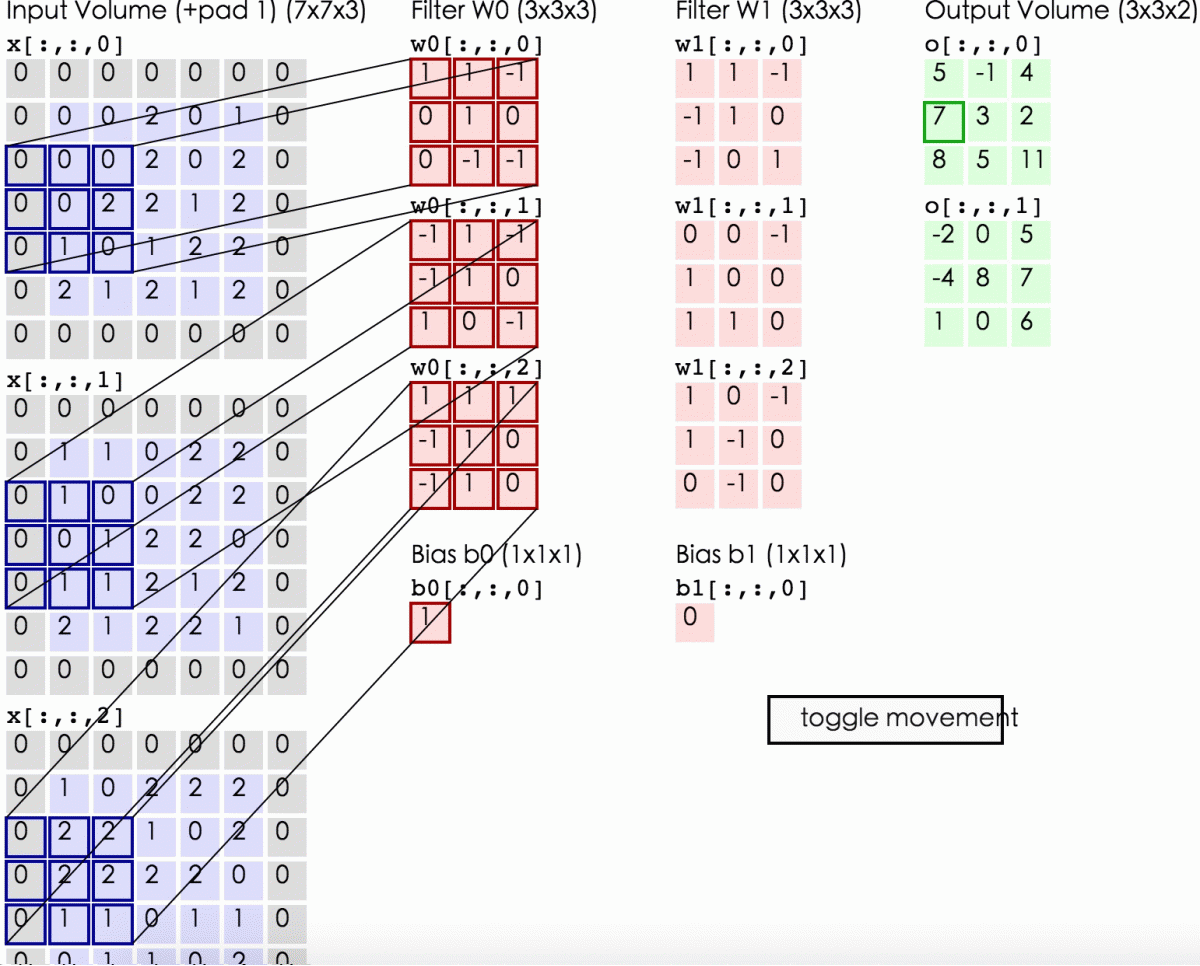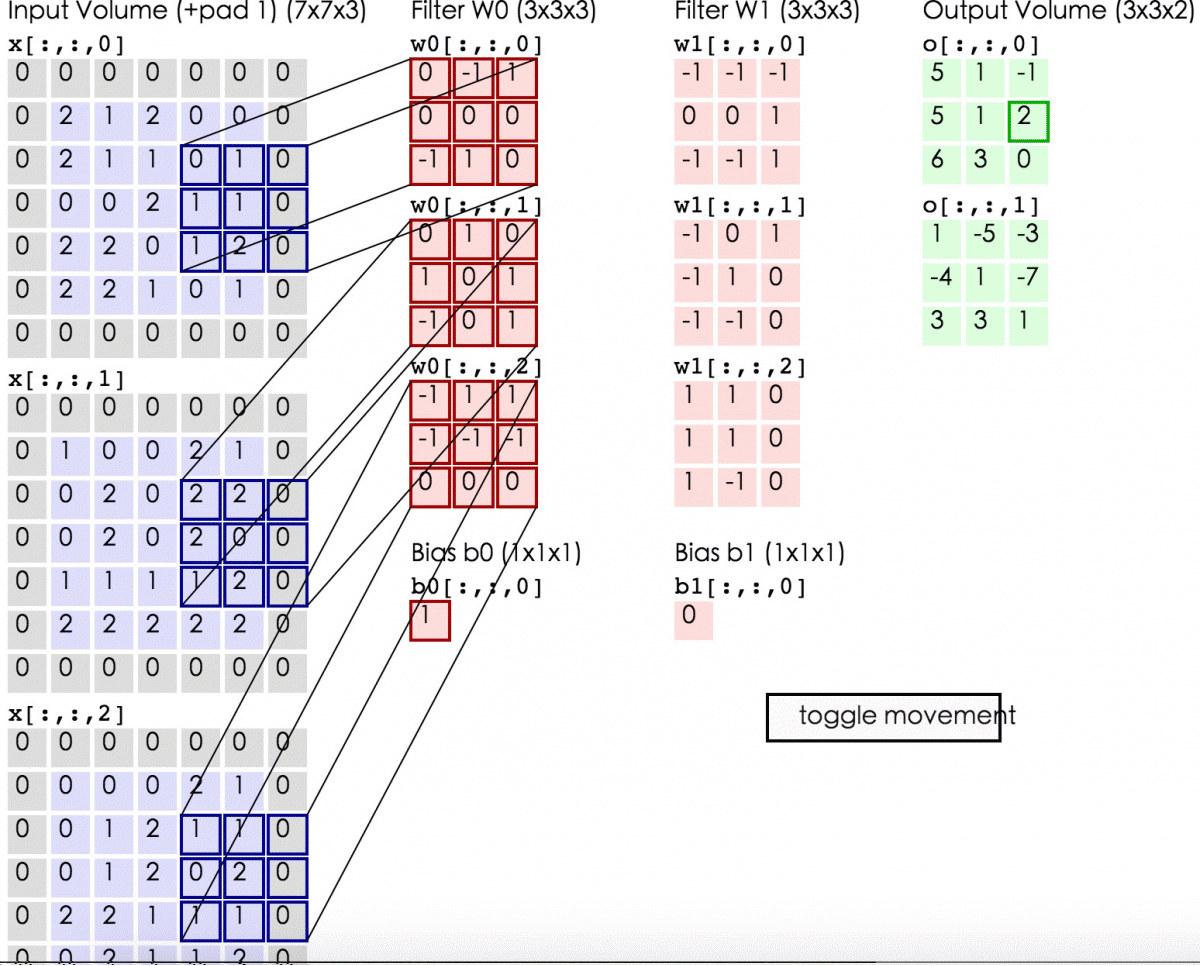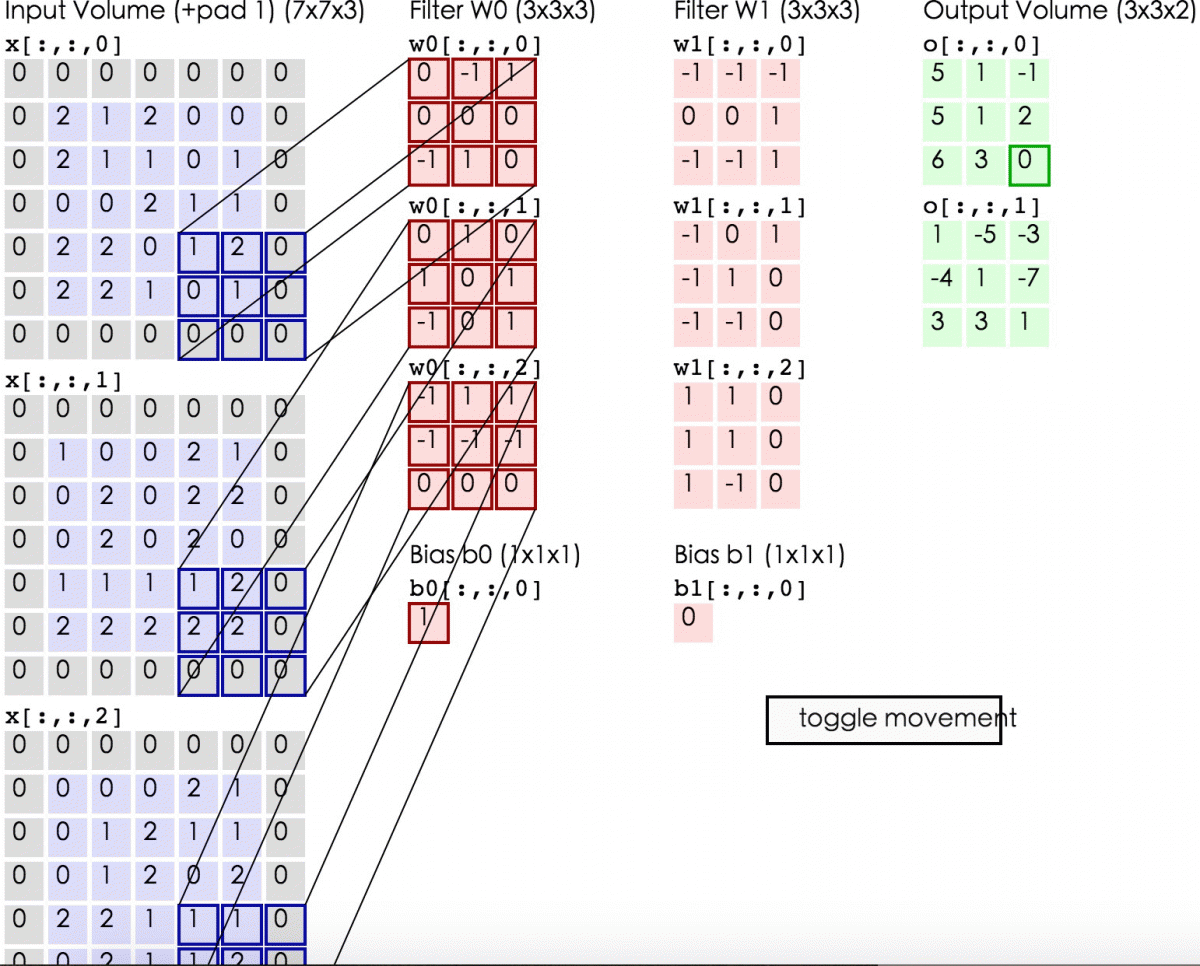 这是一张动态的卷积层计算图,图上的zero-padding为1,所以大家可以看到数据左右各补了一行0,窗口的长宽为3,滑动步长stride为2。
这是一张动态的卷积层计算图,图上的zero-padding为1,所以大家可以看到数据左右各补了一行0,窗口的长宽为3,滑动步长stride为2。
关于zero-padding,补0这个操作产生的根本原因是,为了保证窗口的滑动能从头刚好到尾。举个例子说,上2图中的上面一幅图,因为(data_len-receptive_field_len+2*zero-padding)/stride刚好能够整除,所以窗口左侧贴着数据开始位置,滑到尾部刚好窗口右侧能够贴着数据尾部位置,因此是不需要补0的。而在下面那幅图中,如果滑动步长设为4,你会发现第一次计算之后,窗口就无法『滑动』了,而尾部的数据,是没有被窗口『看到过』的,因此补0能够解决这个问题。
关于窗口滑动步长。大家可以发现一点,窗口滑动步长设定越小,两次滑动取得的数据,重叠部分越多,但是窗口停留的次数也会越多,运算律大一些;窗口滑动步长设定越长,两次滑动取得的数据,重叠部分越少,窗口停留次数也越少,运算量小,但是从一定程度上说数据信息不如上面丰富了。
卷积层的参数共享
首先得说卷积层的参数共享是一个非常赞的处理方式,它使得卷积神经网络的训练计算复杂度和参数个数降低非常非常多。就拿实际解决ImageNet分类问题的卷积神经网络结构来说,我们知道输出结果有555596=290400个神经元,而每个神经元因为和窗口内数据的连接,有11113=363个权重和1个偏移量。所以总共有290400*364=105705600个权重。。。然后。。。恩,训练要累挂了。。。
因此我们做了一个大胆的假设,我们刚才提到了,每一个神经元可以看做一个filter,对图片中的数据窗区域做『过滤』。那既然是filter,我们干脆就假设这个神经元用于连接数据窗的权重是固定的,这意味着,对同一个神经元而言,不论上一层数据窗口停留在哪个位置,连接两者之间的权重都是同一组数。那代表着,上面的例子中的卷积层,我们只需要 神经元个数数据窗口维度=9611113=34848个权重。
如果对应每个神经元的权重是固定的,那么整个计算的过程就可以看做,一组固定的权重和不同的数据窗口数据做内积的过程,这在数学上刚好对应『卷积』操作,这也就是卷积神经网的名字来源。另外,因为每个神经元的权重固定,它可以看做一个恒定的filter,比如上面96个神经元作为filter可视化之后是如下的样子:
 需要说明的一点是,参数共享这个策略并不是每个场景下都合适的。有一些特定的场合,我们不能把图片上的这些窗口数据都视作作用等同的。一个很典型的例子就是人脸识别,一般人的面部都集中在图像的中央,因此我们希望,数据窗口滑过这块区域的时候,权重和其他边缘区域是不同的。我们有一种特殊的层对应这种功能,叫做局部连接层/Locally-Connected Layer
需要说明的一点是,参数共享这个策略并不是每个场景下都合适的。有一些特定的场合,我们不能把图片上的这些窗口数据都视作作用等同的。一个很典型的例子就是人脸识别,一般人的面部都集中在图像的中央,因此我们希望,数据窗口滑过这块区域的时候,权重和其他边缘区域是不同的。我们有一种特殊的层对应这种功能,叫做局部连接层/Locally-Connected Layer
卷积层的简单numpy实现
我们假定输入到卷积层的数据为X,加入X的维度为X.shape: (11,11,4)。假定我们的zero-padding为0,也就是左右上下不补充0数据,数据窗口大小为5,窗口滑动步长为2。那输出数据的长宽应该为(11-5)/2+1=4。假定第一个神经元对应的权重和偏移量分别为W0和b0,那我们就能算得,在第一行数据窗口停留的4个位置,得到的结果值分别为:
V[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0
V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0
V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0
V[3,0,0] = np.sum(X[6:11,:5,:] * W0) + b0
注意上述计算过程中,*运算符是对两个向量进行点乘的,因此W0应该维度为(5,5,4),同样你可以计算其他位置的计算输出值:
V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1
V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1
V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1
V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1
V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1 (在y方向上)
V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1 (或两个方向上同时)
每一个神经元对应不同的一组W和b,在每个数据窗口停留的位置,得到一个输出值。
我们之前提到了卷积层在做的事情,是不断做权重和窗口数据的点乘和求和。因此我们也可以把这个过程整理成一个大的矩阵乘法。
- 看看数据端,我们可以做一个操作im2col将数据转成一个可直接供神经元filter计算的大矩阵。举个例子说,输入是[2272273]的图片,而神经元权重为[11113],同时窗口移动步长为4,那我们知道数据窗口滑动过程中总共产生[(227-11)/4+1][(227-11)/4+1]=5555=3025个局部数据区域,又每个区域包含11113=363个数据值,因此我们想办法把原始数据重复和扩充成一个[363*3025]的数据矩阵X_col,就可以直接和filter进行运算了。
- 对于filter端(卷积层),假如厚度为96(有96个不同权重组的filter),每个filter的权重为[11113],因此filter矩阵W_row维度为[96*363]
- 在得到上述两个矩阵后,我们的输出结果即可以通过np.dot(W_row, X_col)计算得到,结果数据为[96*3025]维的。
这个实现的弊端是,因为数据窗口的滑动过程中有重叠,因此我们出现了很多重复数据,占用内存较大。好处是,实际计算过程非常简单,如果我们用类似BLAS这样的库,计算将非常迅速。
另外,在反向传播过程中,其实卷积对应的操作还是卷积,因此实现起来也很方便。
Pooling层
简单说来,在卷积神经网络中,Pooling层是夹在连续的卷积层中间的层。它的作用也非常简单,就是逐步地压缩/减少数据和参数的量,也在一定程度上减小过拟合的现象。Pooling层做的操作也非常简单,就是将原数据上的区域压缩成一个值(区域最大值/MAX或者平均值/AVERAGE),最常见的Pooling设定是,将原数据切成2*2的小块,每块里面取最大值作为输出,这样我们就自然而然减少了75%的数据量。需要提到的是,除掉MAX和AVERAGE的Pooling方式,其实我们也可以设定别的pooling方式,比如L2范数pooling。说起来,历史上average pooling用的非常多,但是近些年热度降了不少,工程师们在实践中发现max pooling的效果相对好一些。
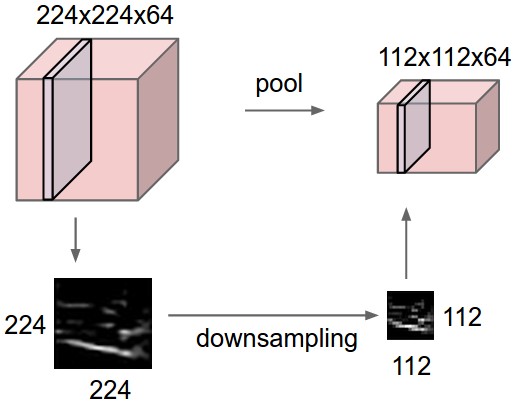
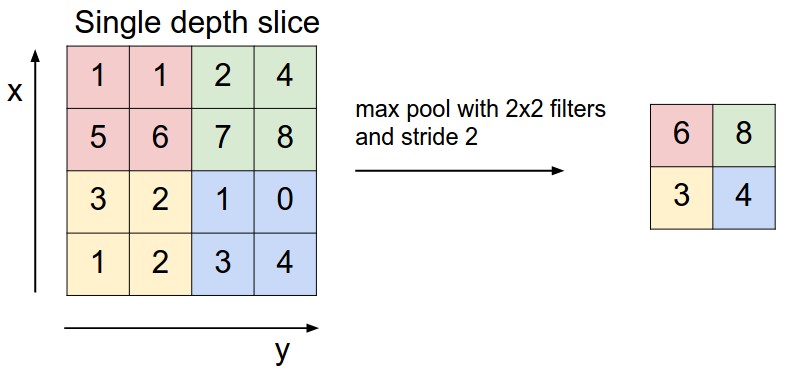 上图为Pooling层的一个直观示例,相当于对厚度为64的data,每一个切片做了一个下采样。下图为Pooling操作的实际max操作。
上图为Pooling层的一个直观示例,相当于对厚度为64的data,每一个切片做了一个下采样。下图为Pooling操作的实际max操作。
Pooling层(假定是MAX-Pooling)在反向传播中的计算也是很简单的,大家都知道如何去求max(x,y)函数的偏导。
归一化层(Normalization Layer)
卷积神经网络里面有时候会用到各种各样的归一化层,尤其是早期的研究,经常能见到它们的身影,不过近些年来的研究表明,似乎这个层级对最后结果的帮助非常小,所以后来大多数时候就干脆拿掉了。
全连接层
在全连接层中,神经元对于前一层中的所有激活数据是全部连接的,这个常规神经网络中一样。它们的激活可以先用矩阵乘法,再加上偏差。
把全连接层转化成卷积层
全连接层和卷积层之间唯一的不同就是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数。然而在两类层中,神经元都是计算点积,所以它们的函数形式是一样的。因此,将此两者相互转化是可能的:
- 对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层。权重矩阵是一个巨大的矩阵,除了某些特定块(这是因为有局部连接),其余部分都是零。而在其中大部分块中,元素都是相等的(因为参数共享)。
- 相反,任何全连接层都可以被转化为卷积层。比如,一个K=4096的全连接层,输入数据体的尺寸是77512,这个全连接层可以被等效地看做一个F=7,P=0,S=1,K=4096的卷积层。换句话说,就是将滤波器的尺寸设置为和输入数据体的尺寸一致了。因为只有一个单独的深度列覆盖并滑过输入数据体,所以输出将变成114096,这个结果就和使用初始的那个全连接层一样了。
全连接层转化为卷积层:在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。假设一个卷积神经网络的输入是224x224x3的图像,一系列的卷积层和汇聚层将图像数据变为尺寸为7x7x512的激活数据体(在AlexNet中就是这样,通过使用5个汇聚层来对输入数据进行空间上的降采样,每次尺寸下降一半,所以最终空间尺寸为224/2/2/2/2/2=7)。从这里可以看到,AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。我们可以将这3个全连接层中的任意一个转化为卷积层:
- 针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
- 针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
- 对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
实际操作中,每次这样的变换都需要把全连接层的权重W重塑成卷积层的滤波器。那么这样的转化有什么作用呢?它在下面的情况下可以更高效:让卷积网络在一张更大的输入图片上滑动,即把一张更大的图片的不同区域都分别带入到卷积网络,得到每个区域的得分,得到多个输出,这样的转化可以让我们在单个向前传播的过程中完成上述的操作。
举个例子,如果我们想让224x224尺寸的浮窗,以步长为32在384x384的图片上滑动,把每个经停的位置都带入卷积网络,最后得到6x6个位置的类别得分。上述的把全连接层转换成卷积层的做法会更简便。如果224x224的输入图片经过卷积层和汇聚层之后得到了[7x7x512]的数组,那么,384x384的大图片直接经过同样的卷积层和汇聚层之后会得到[12x12x512]的数组(因为途径5个汇聚层,尺寸变为384/2/2/2/2/2 = 12)。然后再经过上面由3个全连接层转化得到的3个卷积层,最终得到[6x6x1000]的输出(因为(12 - 7)/1 + 1 = 6)。这个结果正是浮窗在原图经停的6x6个位置的得分!(译者注:这一段的翻译与原文不同,经过了译者较多的修改,使更容易理解)
面对384x384的图像,让(含全连接层)的初始卷积神经网络以32像素的步长独立对图像中的224x224块进行多次评价,其效果和使用把全连接层变换为卷积层后的卷积神经网络进行一次前向传播是一样的。
自然,相较于使用被转化前的原始卷积神经网络对所有36个位置进行迭代计算,使用转化后的卷积神经网络进行一次前向传播计算要高效得多,因为36次计算都在共享计算资源。这一技巧在实践中经常使用,一次来获得更好的结果。比如,通常将一张图像尺寸变得更大,然后使用变换后的卷积神经网络来对空间上很多不同位置进行评价得到分类评分,然后在求这些分值的平均值。
最后,如果我们想用步长小于32的浮窗怎么办?用多次的向前传播就可以解决。比如我们想用步长为16的浮窗。那么先使用原图在转化后的卷积网络执行向前传播,然后分别沿宽度,沿高度,最后同时沿宽度和高度,把原始图片分别平移16个像素,然后把这些平移之后的图分别带入卷积网络。
搭建卷积神经网结构
从上面的内容我们知道,卷积神经网络一般由3种层搭建而成:卷积层,POOLing层(我们直接指定用MAX-Pooling)和全连接层。然后我们一般选用最常见的神经元ReLU,我们来看看有这些『组件』之后,怎么『拼』出一个合理的卷积神经网。
层和层怎么排
最常见的组合方式是,用ReLU神经元的卷积层组一个神经网络,同时在卷积层和卷积层之间插入Pooling层,经过多次的[卷积层]=>[Pooling层]叠加之后,数据的总体量级就不大了,这个时候我们可以放一层全连接层,然后最后一层和output层之间是一个全连接层。所以总结一下,最常见的卷积神经网结构为:
[输入层] => [[ReLU卷积层]N => [Pooling层]?]M => [ReLU全连接层]*K => [全连接层]
解释一下,其中*操作代表可以叠加很多层,而[Pooling层]?表示Pooling层其实是可选的,可有可无。N和M是具体层数。比如说[输入层] -> [[ReLU卷积层]=>[ReLU卷积层]=>[Pooling层]]3 -> [ReLU全连接层]2 -> [全连接层]就是一个合理的深层的卷积神经网。
『在同样的视野范围内,选择多层叠加的卷积层,而不是一个大的卷积层』
这句话非常拗口,但这是实际设计卷积神经网络时候的经验,我们找个例子来解释一下这句话:如果你设计的卷积神经网在数据层有3层连续的卷积层,同时每一层滑动数据窗口为33,第一层每个神经元可以同时『看到』33的原始数据层,那第二层每个神经元可以『间接看到』(1+3+1)(1+3+1)=55的数据层内容,第三层每个神经元可以『间接看到』(1+5+1)(1+5+1)=77的数据层内容。那从最表层看,还不如直接设定滑动数据窗口为7*7的,为啥要这么设计呢,我们来分析一下优劣:
- 虽然第三层对数据层的『视野』范围是一致的。但是单层卷积层加77的上层滑动数据窗口,结果是这7个位置的数据,都是线性组合后得到最后结果的;而3层卷积层加33的滑动数据窗口,得到的结果是原数据上7*7的『视野』内数据多层非线性组合,因此这样的特征也会具备更高的表达能力。
- 如果我们假设所有层的『厚度』/channel数是一致的,为C,那77的卷积层,会得到$C×(7×7×C)=49C^2$个参数,而3层叠加的33卷积层只有$3×(C×(3×3×C))=27C^2$个参数。在计算量上后者显然是有优势的。
- 同上一点,我们知道为了反向传播方便,实际计算过程中,我们会在前向计算时保留很多中间梯度,3层叠加的3*3卷积层需要保持的中间梯度要小于前一种情况,这在工程实现上是很有好处的。
层大小的设定
话说层级结构确定了,也得知道每一层大概什么规模啊。现在我们就来聊聊这个。说起来,每一层的大小(神经元个数和排布)并没有严格的数字规则,但是我们有一些通用的工程实践经验和系数:
- 对于输入层(图像层),我们一般把数据归一化成2的次方的长宽像素值。比如CIFAR-10是32323,STL-10数据集是64643,而ImageNet是2242243或者5125123。
- 卷积层通常会把每个[滤子/filter/神经元]对应的上层滑动数据窗口设为33或者55,滑动步长stride设为1(工程实践结果表明stride设为1虽然比较密集,但是效果比较好,步长拉太大容易损失太多信息),zero-padding就不用了。
- Pooling层一般采用max-pooling,同时设定采样窗口为2*2。偶尔会见到设定更大的采样窗口,但是那意味着损失掉比较多的信息了。
- 比较重要的是,我们得预估一下内存,然后根据内存的情况去设定合理的值。我们举个例子,在ImageNet分类问题中,图片是2242243的,我们跟在数据层后面3个33『视野窗』的卷积层,每一层64个filter/神经元,把padding设为1,那么最后每个卷积层的output都是[22422464],大概需要1000万次对output的激励计算(非线性activation),大概花费72MB内存。而工程实践里,一般训练都在GPU上进行,GPU的内存比CPU要吃紧的多,所以也许我们要稍微调动一下参数。比如AlexNet用的是1111的的视野窗,滑动步长为4。
考虑点
组一个实际可用的卷积神经网络最大的瓶颈是GPU的内存。毕竟现在很多GPU只有3/4/6GB的内存,最大的GPU也就12G内存,所以我们应该在设计卷积神经网的时候多加考虑:
- 很大的一部分内存开销来源于卷积层的激励函数个数和保存的梯度数量。
- 保存的权重参数也是内存的主要消耗处,包括反向传播要用到的梯度,以及你用momentum, Adagrad, or RMSProp这些算法时候的中间存储值。
- 数据batch以及其他的类似版本信息或者来源信息等也会消耗一部分内存。
更多的卷积神经网络参考资料
DeepLearning.net tutorial是一个用Theano完整实现卷积神经网的教程。
cuda-convnet2是多GPU并行化的实现。
ConvNetJS CIFAR-10 demo允许你手动设定参数,然后直接在浏览器看卷积神经网络的结果。
Caffe,主流卷积神经网络开源库之一。
Example Torch 7 ConvNet,在CIFAR-10上错误率只有7%的卷积神经网络实现。
Ben Graham’s Sparse ConvNet,CIFAR-10上错误率只有4%的实现。
Face recognition for right whales using deep learning,Kaggle看图识别濒临灭绝右鲸比赛的冠军队伍卷积神经网络。
深度学习与计算机视觉系列(10)_细说卷积神经网络