1,逻辑回归问题
有一组病人的数据,我们需要预测他们在一段时间后患上心脏病的“可能性”,就是我们要考虑的问题。
通过二值分类,我们仅仅能够预测病人是否会患上心脏病,不同于此的是,现在我们还关心患病的可能性,即 f(x) = P(+1|x),取值范围是区间 [0,1]。
然而,我们能够获取的训练数据却与二值分类完全一样,x 是病人的基本属性,y 是+1(患心脏病)或 -1(没有患心脏病)。输入数据并没有告诉我们有关“概率” 的信息。
在二值分类中,我们通过w*x 得到一个”score” 后,通过取符号运算sign 来预测y 是+1 或 -1。而对于当前问题,我们如同能够将这个score 映射到[0,1] 区间,问题似乎就迎刃而解了。
逻辑斯蒂回归选择的映射函数是S型的sigmoid 函数。sigmoid 函数: f(s) = 1 / (1 + exp(-s)), s 取值范围是整个实数域, f(x) 单调递增,0 <= f(x) <= 1。
于是,我们有:
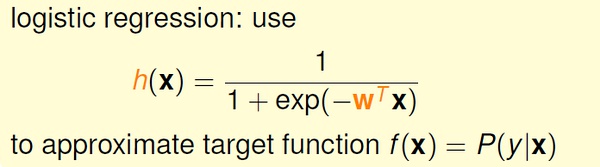
2,逻辑斯蒂回归的优化方法
对于上面的公式,如何定义Ein(w) 呢?
| logistic regression 的目标是 f(x) = P(+1 | x): |
| 当y = +1 时, P(y | x) = f(x); |
| 当y = -1 时, P(y | x) = 1 - f(x). |
在机器学习假设中,数据集D 是由f 产生的,我们可以按照这个思路,考虑f 和假设 h 生成训练数据D的概率:

训练数据的客观存在的,显然越有可能生成该数据集的假设越好。
 通过一些列简单转换,我们得到最终的优化目标函数:
通过一些列简单转换,我们得到最终的优化目标函数:
 注意上图中”cross-entropy error” 的定义。
注意上图中”cross-entropy error” 的定义。
3,LR Error 的梯度

Ein(w) 的微分结果是:
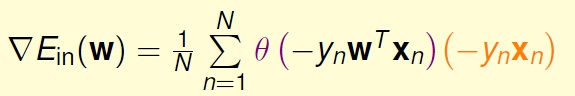
想要上式等于零,或者sigmoid 项恒为0,这时要求数据时线性可分的(不能有噪音)。
否则,需要迭代优化。直观的优化方法:

4, 梯度下降法
梯度下降法是最经典、最常见的优化方法之一。
要寻找目标函数曲线的波谷,采用贪心法:想象一个小人站在半山腰,他朝哪个方向跨一步,可以使他距离谷底更近(位置更低),就朝这个方向前进。这个方向可以通过微分得到。
选择足够小的一段曲线,可以将这段看做直线段,那么有:
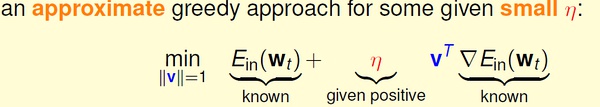 梯度下降的精髓:
梯度下降的精髓:
 之所以说最优的v 是与梯度相反的方向,想象一下:如果一条直线的斜率k>0,说明向右是上升的方向,应该向左走;反之,斜率k<0,向右走。
之所以说最优的v 是与梯度相反的方向,想象一下:如果一条直线的斜率k>0,说明向右是上升的方向,应该向左走;反之,斜率k<0,向右走。
解决的方向问题,步幅也很重要。步子太小的话,速度太慢;过大的话,容易发生抖动,可能到不了谷底。
显然,距离谷底较远(位置较高)时,步幅大些比较好;接近谷底时,步幅小些比较好(以免跨过界)。距离谷底的远近可以通过梯度(斜率)的数值大小间接反映,接近谷底时,坡度会减小。
因此,我们希望步幅与梯度数值大小正相关。
原式子可以改写为:
 最后,完整的Logistic Regression Algorithm:
最后,完整的Logistic Regression Algorithm:
