当我们面对的问题不是完美的(无噪音)二值分类问题,VC 理论还有效吗?
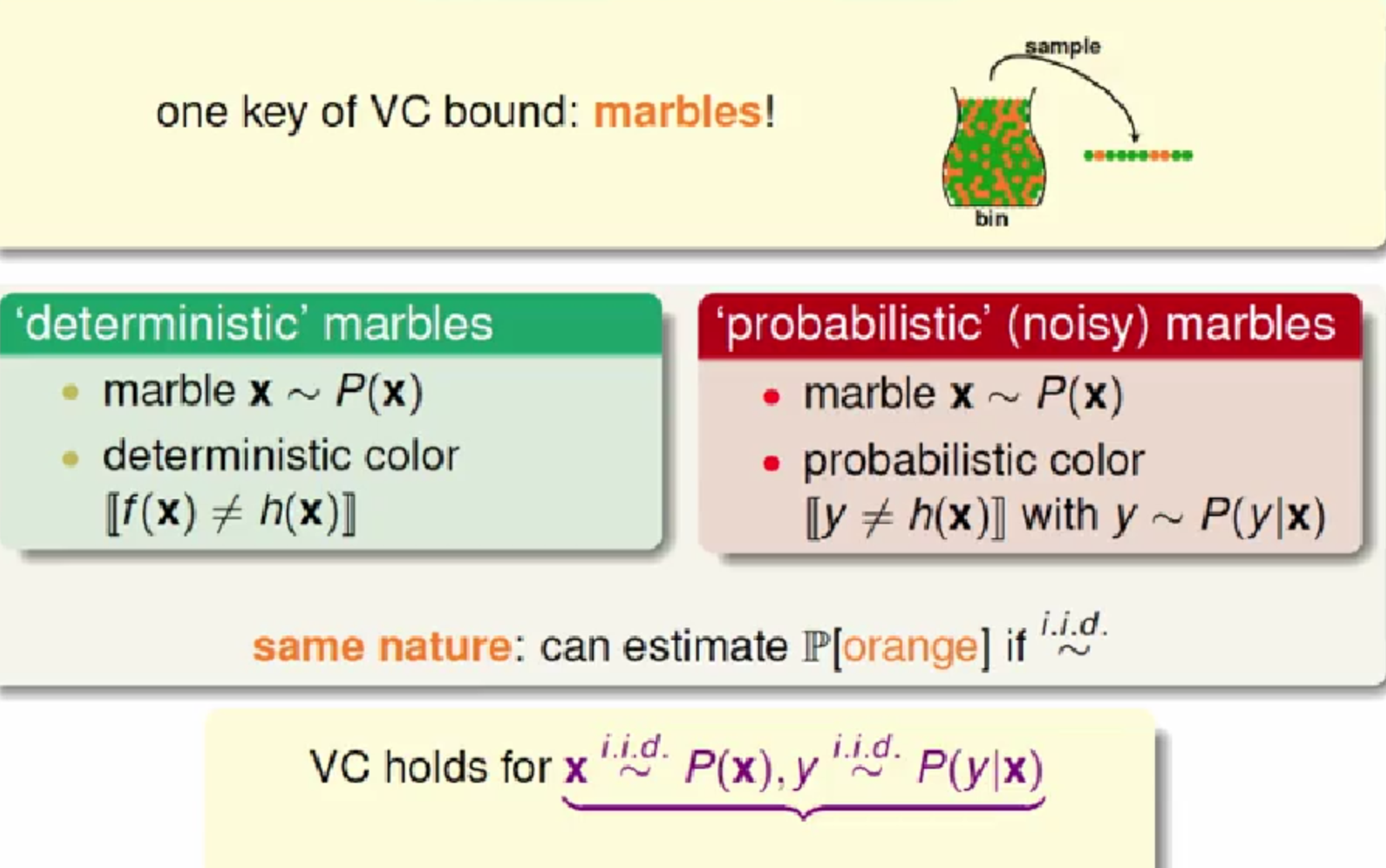
1,噪音和非确定性目标
几种错误:(1) noise in y: mislabeled data; (2) noise in y: different labels for same x; (3) noise in x: error x.
将包含噪音的y 看作是概率分布的,y ~ P(y|x)。
学习的目标变为预测最有可能出现的y,max {P(y|x)}。
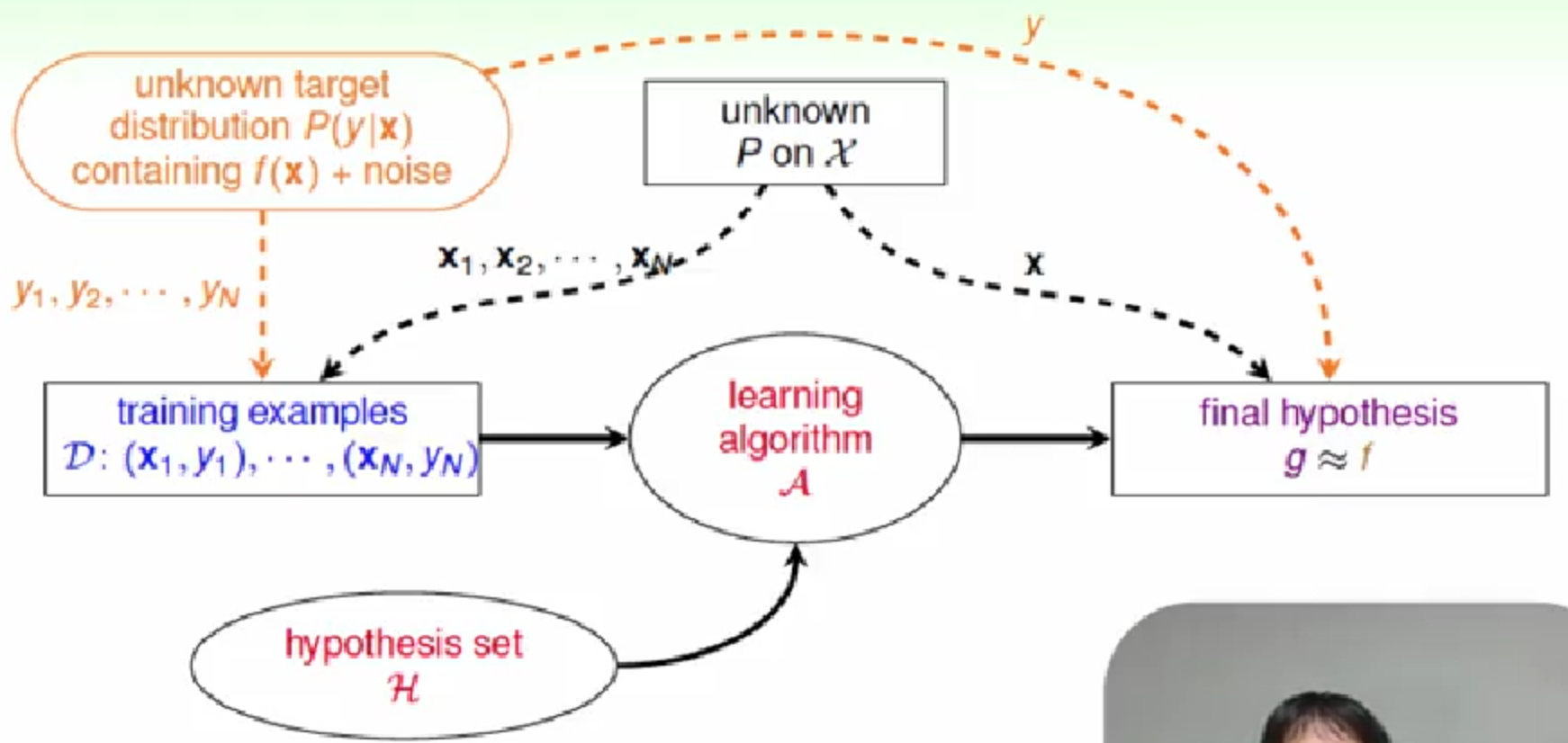
2, 错误的测量 (error measure)
对错误不同的测量方法将对学习过程有不同的指导。
如下面的0/1 error 和 squared error.
 我们在学习之前,需要告诉模型我们所关心的指标或衡量错误的方法。
我们在学习之前,需要告诉模型我们所关心的指标或衡量错误的方法。
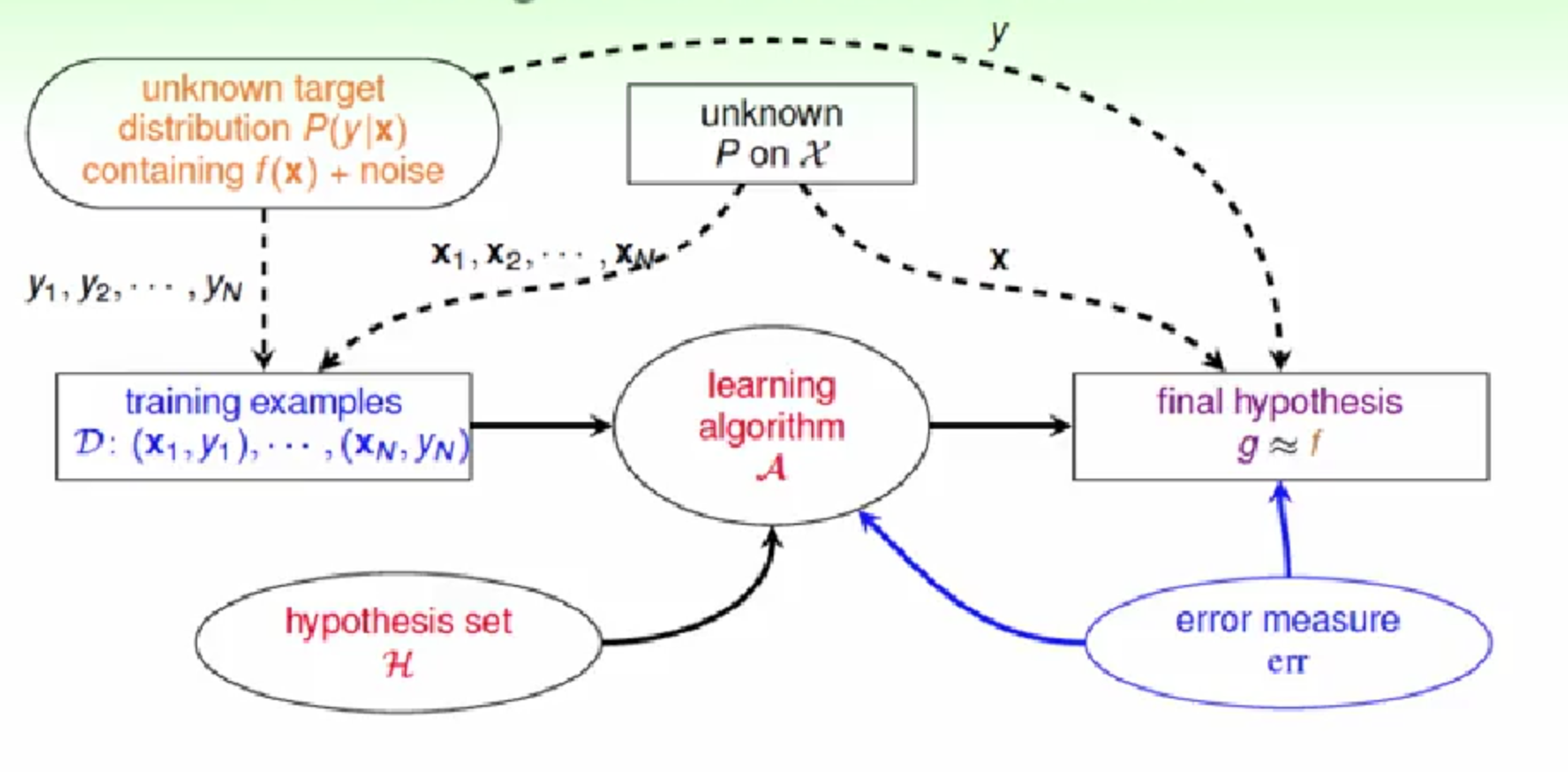
3,衡量方法的选择

图中的false accept 和 false reject 就是我们在分类中常说的 false positive 和 false negative,只是台湾和大陆的叫法不同而已。
采用0/1 error 时,对于每种错误,都会有相同程度的惩罚(panalize)。
然而,在实际应用中,两种错误带来的影响可能很不一样。
例如(讲义中的例子),一个商场对顾客进行分类,老顾客可以拿到折扣,新顾客没有折扣;这时,如果发生false reject(将老顾客错分为新顾客)而不给其打折,那么会严重影响用户体验,对商家口碑造成损失,影响较坏;而如果发生false accept (将新顾客错分为老顾客)而给其打折,也没什么大不了的。
另一个例子,CIA 的安全系统身份验证,如果发生false accept(将入侵者错分为合法雇员),后果非常严重。
通过上述两个例子,我们知道,对于不同application,两类错误的影响是完全不同的,因此在学习时应该通过赋予不同的权重来区分二者。比如对于第二个例子,当发生false accept : f(x)=-1, g(x)=+1, 对Ein 加一个很大的值。
Just remember: error is application/user-dependent

4,带权重的分类
依然是借助CIA 身份验证的例子来说明什么是weighted classification:
 通过感知机模型解决CIA 分类问题。如果数据时线性可分的,那么带权重与否对结果没有影响,我们总能得到理想结果。
通过感知机模型解决CIA 分类问题。如果数据时线性可分的,那么带权重与否对结果没有影响,我们总能得到理想结果。
如果输入数据有噪音(线性不可分),像前面学习感知机时一样,采用Pocket 方法,然而计算错误时对待两种错误(false reject/false accept) 不再一视同仁,false acceot 比false reject 严重1000倍。通过下面方法解决:

即,在训练开始前,我们将{(x,y),y=-1} 的数据复制1000倍之后再开始学习,后面的步骤与传统的pocket 方法一模一样。
然而,从效率、计算资源的角度考虑,通常不会真的将y=-1 的数据拷贝1000倍,实际中一般采用”virtual copying”。只要保证:
randomly check -1 example mistakes with 1000 times more probability.
(这句大家还是看英文比较好,以免理解有歧义)
 总之,我们选择好适合特定应用的error measure: err,然后在训练时力求最小化err,即,我们要让最后的预测发生错误的可能性最小(错误测量值最小),这样的学习是有效的。
总之,我们选择好适合特定应用的error measure: err,然后在训练时力求最小化err,即,我们要让最后的预测发生错误的可能性最小(错误测量值最小),这样的学习是有效的。