我们已经知道,车牌定位模块的输出是一些候选车牌的图片。但如何从这些候选车牌图片中甄选出真正的车牌,就是通过SVM模型判断/预测得到的。
简单来说,EasyPR的车牌判断模块就是将候选车牌的图片一张张地输入到SVM模型中,然后问它,这是车牌么?如果SVM模型回答不是,那么就继续下一张,如果是,则把图片放到一个输出列表里。最后把列表输入到下一步处理。由于EasyPR使用的是列表作为输出,因此它可以输出一副图片中所有的车牌,不像一些车牌识别程序,只能输出一个车牌结果。
现在,让我们一步步地,进入这个SVM模型的核心看看,它是如何做到判断一副图片是车牌还是不是车牌的?本文主要分为三个大的部分:
- SVM应用:描述如何利用SVM模型进行车牌图片的判断。
- SVM训练:说明如何通过一系列步骤得到SVM模型。
- SVM调优:讨论如何对SVM模型进行优化,使其效果更加好。
SVM应用
我们在SVM模型中一开始输入的原始信息也是图像的所有像素,然后SVM模型通过对这些像素进行分析,输出这个图片是否是车牌的结论。
int PlateJudge::plateJudge(const Mat &inMat, int &result) {
Mat features;
extractFeature(inMat, features);
float response = svm_->predict(features);
/*std::cout << "response:" << response << std::endl;
float score = svm_->predict(features, noArray(), cv::ml::StatModel::Flags::RAW_OUTPUT);
std::cout << "score:" << score << std::endl;*/
result = (int)response;
return 0;
}
SVM训练
简而言之,SVM训练部分的目标就是通过一批数据,然后生成一个代表我们模型的xml文件。
一个训练过程包含5个步骤,见下图:
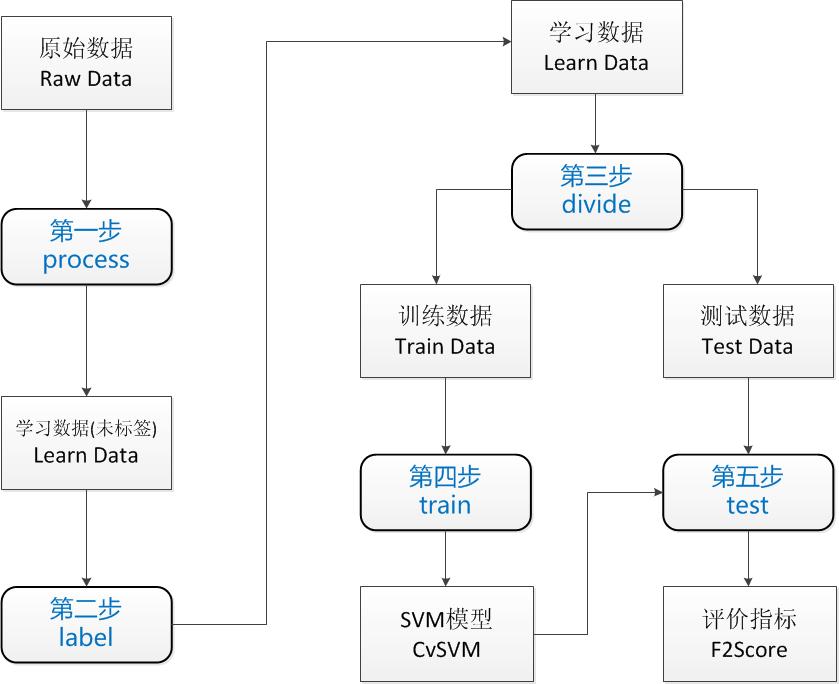
下面具体讲解一下这5个步骤,步骤后面的括号里代表的是这个步骤主要的输入与输出。
1. preprocss(原始数据->学习数据(未标签))
预处理步骤主要处理的是原始数据到学习数据的转换过程。原始数据(raw data),表示你一开始拿到的数据。这些数据的情况是取决你具体的环境的,可能有各种问题。学习数据(learn data),是可以被输入到模型的数据。
为了能够进入模型训练,必须将原始数据处理为学习数据,同时也可能进行了数据的筛选。比方说你有10000张原始图片,出于性能考虑,你只想用1000张图片训练,那么你的预处理过程就是将这10000张处理为符合训练要求的1000张。你生成的1000张图片中应该包含两类数据:真正的车牌图片和不是车牌的图片。如果你想让你的模型能够区分这两种类型。你就必须给它输入这两类的数据。
通过EasyPR的车牌定位模块PlateLocate可以生成大量的候选车牌图片,里面包括模型需要的车牌和非车牌图片。但这些候选车牌是没有经过分类的,也就是说没有标签。下步工作就是给这些数据贴上标签。
2. label (学习数据(未标签)->学习数据)
训练过程的第二步就是将未贴标签的数据转化为贴过标签的学习数据。我们所要做的工作只是将车牌图片放到一个文件夹里,非车牌图片放到另一个文件夹里。
3. divide (学习数据->分组数据)
在贴完标签以后,我拥有了车牌图片和非车牌图片共几千张。在我直接训练前,不急。先拿出30%的数据,只用剩下的70%数据进行SVM模型的训练,训练好的模型再用这30%数据进行一个效果测试。这30%数据充当的作用就是一个评判数据测试集,称之为test data,另70%数据称之为train data。于是一个完整的learn data被分为了train data和test data。
4. train (训练数据->模型)
模型在代码里的代表就是CvSVM类。在这一步中所要做的就是加载traindata,然后用CvSVM类的train方法进行训练。这个步骤只针对的是上步中生成的总数据70%的训练数据。
具体来说,分为以下几个子步骤:
1) 加载待训练的车牌数据。见下面这段代码。
int readFileList(char *basePath,vector<string>& files)
{
DIR *dir;
struct dirent *ptr;
char base[1000];
if ((dir=opendir(basePath)) == NULL)
{
perror("Open dir error...");
exit(1);
}
string result;
char temp[100];
while ((ptr=readdir(dir)) != NULL)
{
if(strcmp(ptr->d_name,".")==0 || strcmp(ptr->d_name,"..")==0) ///current dir OR parrent dir
continue;
else if(ptr->d_type == 8) { ///file
//printf("d_name:%s/%s\n",basePath,ptr->d_name);
sprintf(temp, "%s/%s", basePath, ptr->d_name);
//cout<<temp<<endl;
result = temp;
files.push_back(result);
//cout<<result<<endl;
}
else if(ptr->d_type == 10) ///link file
printf("d_name:%s/%s\n",basePath,ptr->d_name);
else if(ptr->d_type == 4) ///dir
{
memset(base,'\0',sizeof(base));
strcpy(base,basePath);
strcat(base,"/");
strcat(base,ptr->d_name);
readFileList(base,files);
}
}
closedir(dir);
return 1;
}
void getPlate(Mat& trainingImages, vector<int>& trainingLabels)
{
char * filePath = "train/data/plate_detect_svm/HasPlate/HasPlate";
vector<string> files;
readFileList(filePath, files );
int size = files.size();
if (0 == size)
cout << "No File Found in train HasPlate!" << endl;
for (int i = 0;i < size;i++)
{
cout << files[i].c_str() << endl;
Mat img = imread(files[i].c_str());
img= img.reshape(1, 1);
trainingImages.push_back(img);
trainingLabels.push_back(1);
}
}
注意看,车牌图像我存储在的是一个vector
2) 加载待训练的非车牌数据,见下面这段代码中的函数。基本内容与加载车牌数据类似,不同之处在于文件夹是train/NoPlate,并且我往vector
3) 将两者合并。目前拥有了两个vector
Mat classes;//(numPlates+numNoPlates, 1, CV_32FC1);
Mat trainingData;//(numPlates+numNoPlates, imageWidth*imageHeight, CV_32FC1 );
Mat trainingImages;
vector<int> trainingLabels;
getPlate(trainingImages, trainingLabels);
getNoPlate(trainingImages, trainingLabels);
Mat(trainingImages).copyTo(trainingData);
trainingData.convertTo(trainingData, CV_32FC1);
Mat(trainingLabels).copyTo(classes);
4) 配置SVM模型的训练参数。SVM模型的训练需要一个CvSVMParams的对象,这个类是SVM模型中训练对象的参数的组合,如何给这里的参数赋值,是很有讲究的一个工作。注意,这里是SVM训练的核心内容,也是最能体现一个机器学习专家和新手区别的地方。机器学习最后模型的效果差异有很大因素取决与模型训练时的参数,尤其是SVM,有非常多的参数供你配置(见下面的代码)。参数众多是一个问题,更为显著的是,机器学习模型中参数的一点微调都可能带来最终结果的巨大差异。
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::LINEAR);
svm->setDegree(0);
svm->setGamma(1);
svm->setCoef0(0);
svm->setC(1);
svm->setNu(0);
svm->setP(0);
svm->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 1000, 0.01));
5) 开始训练。OK!数据载入完毕,参数配置结束,一切准备就绪,下面就是交给opencv的时间。我们只要将前面的 trainingData,classes,以及CvSVMParams的对象SVM_params交给CvSVM类的train函数就可以。另外,直接使用CvSVM的构造函数,也可以完成训练过程。
svm->train(trainingData,0,classes);
cout << "Svm generate done!" << endl;
svm->save("../train/svm.xml");
5. test (测试数据->评判指标)
记得我们还有30%的测试数据了么?现在是使用它们的时候了。将这些数据以及它们的标签加载如内存,这个过程与加载训练数据的过程是一样的。接着使用我们训练好的SVM模型去判断这些图片。
下面的步骤是对我们的模型做指标评判的过程。首先,测试数据是有标签的数据,这意味着我们知道每张图片是车牌还是不是车牌。另外,用新生成的svm模型对数据进行判断,也会生成一个标签,叫做“预测标签”。“预测标签”与“标签”一般是存在误差的,这也就是模型的误差。这种误差有两种情况:1.这副图片是真的车牌,但是svm模型判断它是“非车牌”;2.这幅图片不是车牌,但svm模型判断它是“车牌”。无疑,这两种情况都属于svm模型判断失误的情况。我们需要设计出来两个指标,来分别评测这两种失误情况发生的概率。这两个指标就是下面要说的“准确率”(precision)和“查全率”(recall)。
准确率是统计在我已经预测为车牌的图片中,真正车牌数据所占的比例。假设我们用ptrue_rtrue表示预测(p)为车牌并且实际(r)为车牌的数量,而用ptrue_rfalse表示实际不为车牌的数量。
查全率是统计真正的车牌图片中,我预测为车牌的图片所占的比例。同上,我们用ptrue_rtrue表示预测与实际都为车牌的数量。用pfalse_rtrue表示实际为车牌,但我预测为非车牌的数量。
recall的公式与precision公式唯一的区别在于右下角。precision是ptrue_rfalse,代表预测为车牌但实际不是的数量;而recall是pfalse_rtrue,代表预测是非车牌但其实是车牌的数量。
简单来说,precision指标的期望含义就是要“查的准”,recall的期望含义就是“不要漏”。查全率还有一个翻译叫做“召回率”。但很明显,召回这个词没有反映出查全率所体现出的不要漏的含义。
值得说明的是,precise和recall这两个值自然是越高越好。但是如果一个高,一个低的话效果会如何,如何跟两个都中等的情况进行比较?为了能够数字化这种比较。机器学习界又引入了FScore这个数值。当precise和recall两者中任一者较高,而另一者较低是,FScore都会较低。两者中等的情况下Fscore表现比一高一低要好。当两者都很高时,FScore会很高。
注意
回到一个核心问题,对于开发者而言,什么样的方法才是自己实现一个svm.xml的最好方法。有以下几种选择。
1.你使用EasyPR提供的svm.xml,这个方式等同于你没有训练,那么EasyPR识别的效率取决于你的环境与EasyPR的匹配度。运气好的话,这个效果也会不错。但如果你的环境下车牌跟EasyPR默认的不一样。那么可能就会有点问题。
2.使用EasyPR提供的训练数据,例如train/data文件下的数据,这样生成的效果等同于第一步的,不过你可以调整参数,试试看模型的表现会不会更好一点。
3.使用自己的数据进行训练。这个方法的适应性最好。首先你得准备你原始的数据,并且写一个处理方法,能够将原始数据转化为学习数据。下面你调用EasyPR的PlateLocate方法进行处理,将候选车牌图片从原图片截取出来。你可以使用逐次迭代自动标签思想,使用EasyPR已有的svm模型对这些候选图片进行预标签。然后再进行肉眼确认和手工调整,以生成标准的贴好标签的数据。后面的步骤就可以按照分组,训练,测试等过程顺次走下去。如果你使用了EasyPR1.1版本,后面的这几个过程已经帮你实现好代码了,你甚至可以直接在命令行选择操作。
以上就是SVM模型训练的部分,通过这个步骤的学习,你知道如何通过已有的数据去训练出一个自己的模型。下面的部分,是对这个训练过程的一个思考,讨论通过何种方法可以改善我最后模型的效果。
三.SVM调优
SVM调优部分,是通过对SVM的原理进行了解,并运用机器学习的一些调优策略进行优化的步骤。
在这个部分里,最好要懂一点机器学习的知识。同时,本部分也会讲的尽量通俗易懂,让人不会有理解上的负担。在EasyPR1.0版本中,SVM模型的代码完全参考了mastering opencv书里的实现思路。从1.1版本开始,EasyPR对车牌判断模块进行了优化,使得模型最后的效果有了较大的改善。
具体说来,本部分主要包括如下几个子部分:1.RBF核;2.参数调优;3.特征提取;4.接口函数;5.自动化。
下面分别对这几个子部分展开介绍。
1.RBF核
SVM中最关键的技巧是核技巧。“核”其实是一个函数,通过一些转换规则把低维的数据映射为高维的数据。在机器学习里,数据跟向量是等同的意思。例如,一个 [174, 72]表示人的身高与体重的数据就是一个两维的向量。在这里,维度代表的是向量的长度。(务必要区分“维度”这个词在不同语境下的含义,有的时候我们会说向量是一维的,矩阵是二维的,这种说法针对的是数据展开的层次。机器学习里讲的维度代表的是向量的长度,与前者不同)
简单来说,低维空间到高维空间映射带来的好处就是可以利用高维空间的线型切割模拟低维空间的非线性分类效果。也就是说,SVM模型其实只能做线型分类,但是在线型分类前,它可以通过核技巧把数据映射到高维,然后在高维空间进行线型切割。高维空间的线型切割完后在低维空间中最后看到的效果就是划出了一条复杂的分线型分类界限。从这点来看,SVM并没有完成真正的非线性分类,而是通过其它方式达到了类似目的,可谓“曲径通幽”。
SVM模型总共可以支持多少种核呢。根据官方文档,支持的核类型有以下几种:
- liner核,也就是无核。
- rbf核,使用的是高斯函数作为核函数。
- poly核,使用多项式函数作为核函数。
- sigmoid核,使用sigmoid函数作为核函数。
liner核和rbf核是所有核中应用最广泛的。
liner核,虽然名称带核,但它其实是无核模型,也就是没有使用核函数对数据进行转换。因此,它的分类效果仅仅比逻辑回归好一点。在EasyPR1.0版中,我们的SVM模型应用的是liner核。我们用的是图像的全部像素作为特征。
rbf核,会将输入数据的特征维数进行一个维度转换,具体会转换为多少维?这个等于你输入的训练量。假设你有500张图片,rbf核会把每张图片的数据转 换为500维的。如果你有1000张图片,rbf核会把每幅图片的特征转到1000维。这么说来,随着你输入训练数据量的增长,数据的维数越多。更方便在高维空间下的分类效果,因此最后模型效果表现较好。
既然选择SVM作为模型,而且SVM中核心的关键技巧是核函数,那么理应使用带核的函数模型,充分利用数据高维化的好处,利用高维的线型分类带来低维空间下的非线性分类效果。但是,rbf核的使用是需要条件的。
当你的数据量很大,但是每个数据量的维度一般时,才适合用rbf核。相反,当你的数据量不多,但是每个数据量的维数都很大时,适合用线型核。
在EasyPR1.0版中,我们用的是图像的全部像素作为特征,那么根据车牌图像的136×36的大小来看的话,就是4896维的数据,再加上我们输入的 是彩色图像,也就是说有R,G,B三个通道,那么数量还要乘以3,也就是14688个维度。这是一个非常庞大的数据量,你可以把每幅图片的数据理解为长度 为14688的向量。这个时候,每个数据的维度很大,而数据的总数很少,如果用rbf核的话,相反效果反而不如无核。
在EasyPR1.1版本时,输入训练的数据有3000张图片,每个数据的特征改用直方统计,共有172个维度。这个场景下,如果用rbf核的话,就会将每个数据的维度转化为与数据总数一样的数量,也就是3000的维度,可以充分利用数据高维化后的好处。
因此可以看出,为了让EasyPR新版使用rbf核技巧,我们给训练数据做了增加,扩充了两倍的数据,同时,减小了每个数据的维度。以此满足了rbf核的使用条件。通过使用rbf核来训练,充分发挥了非线性模型分类的优势,因此带来了较好的分类效果。
但是,使用rbf核也有一个问题,那就是参数设置的问题。在rbf训练的过程中,参数的选择会显著的影响最后rbf核训练出模型的效果。因此必须对参数进行最优选择。
参数调优
传统的参数调优方法是人手完成的。机器学习工程师观察训练出的模型与参数的对应关系,不断调整,寻找最优的参数。由于机器学习工程师大部分时间在调整模型的参数,也有了“机器学习就是调参”这个说法。
幸好,opencv的svm方法中提供了一个自动训练的方法。也就是由opencv帮你,不断改变参数,训练模型,测试模型,最后选择模型效果最好的那些参数。整个过程是全自动的,完全不需要你参与,你只需要输入你需要调整参数的参数类型,以及每次参数调整的步长即可。
Trainauto 使用方法:
vector<float> featureVector;
vector<int> imageClass;
Ptr<ml::TrainData>traindata = ml::TrainData::create(featureVectorOfSample, ml::ROW_SAMPLE, classOfSample);
Ptr<ml::SVM> svm = ml::SVM::create();
svm->setType(ml::SVM::C_SVC);
svm->setKernel(ml::SVM::RBF);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 6000, 1e-8));
svm->trainAuto(traindata, 10, svm->getDefaultGrid(svm->getC()), svm->getDefaultGrid(svm->getGamma()),
svm->getDefaultGrid(svm->getP()),
svm->getDefaultGrid(svm->getNu()),
svm->getDefaultGrid(svm->getCoef0()),
svm->getDefaultGrid(svm->getDegree()), true);
3.特征提取
在rbf核介绍时提到过,输入数据的特征的维度现在是172,那么这个数字是如何计算出来的?现在的特征用的是直方统计函数,也就是先把图像二值化,然后统计图像中一行元素中1的数目,由于输入图像有36行,因此有36个值,再统计图像中每一列中1的数目,图像有136列,因此有136个值,两者相加正好等于172。新的输入数据的特征提取函数就是下面的代码:
// ! EasyPR的getFeatures回调函数
// !本函数是获取垂直和水平的直方图图值
void getHistogramFeatures(const Mat& image, Mat& features)
{
Mat grayImage;
cvtColor(image, grayImage, CV_RGB2GRAY);
Mat img_threshold;
threshold(grayImage, img_threshold, 0, 255, CV_THRESH_OTSU+CV_THRESH_BINARY);
features = getTheFeatures(img_threshold);
}
4.接口函数
由于有SIFT以及HOG等特征没有实现,而且未来有可能会有更多有效的特征函数出现。因此我把特征函数抽象为借口。使用回调函数的思路实现。所有回调函数的代码都在feature.cpp中,开发者可以实现自己的回调函数,并把它赋值给EasyPR中的某个函数指针,从而实现自定义的特征提取。也许你们会有更多更好的特征的想法与创意。
注意,其中使用了typedef,来提取不同的特征:
typedef void (*svmCallback)(const cv::Mat& image, cv::Mat& features);
//! EasyPR的getFeatures回调函数
//! 本函数是获取垂直和水平的直方图图值
void getHistogramFeatures(const cv::Mat& image, cv::Mat& features);
//! 本函数是获取SIFT特征子
void getSIFTFeatures(const cv::Mat& image, cv::Mat& features);
//! 本函数是获取HOG特征子
void getHOGFeatures(const cv::Mat& image, cv::Mat& features);
//! 本函数是获取HSV空间量化的直方图特征子
void getHSVHistFeatures(const cv::Mat& image, cv::Mat& features);
//! LBP feature
void getLBPFeatures(const cv::Mat& image, cv::Mat& features);
//! get character feature
cv::Mat charFeatures(cv::Mat in, int sizeData);
cv::Mat charFeatures2(cv::Mat in, int sizeData);
//! LBP feature + Histom feature
void getLBPplusHistFeatures(const cv::Mat& image, cv::Mat& features);