相关学习网站
R语言常用领域
- 探索性数据分析
- 统计推断
- 回归分析
1.线性模型拟合数据。(预测变量、结果变量),通过预测变量来预测结果变量。
2.预测:利用建立好的线性模型预测未来情况 - 机器学习-分类问题
训练模型+预测 - 开发数据产品
- googlevis API的使用:画地图等
- Manipulate
- rChart:使用R制作交互式javascript可视化产品
- Shiny:制作嵌入网页的交互式R程序的平台:http://www.shinyapps.io/
- Slidify:制作和发布基于R的报告(PPT)
安装
R与RStudio的安装
包的安装
下载r-package:cran、bioconductor、github
- 下载: install.packges()
- 加载:library()
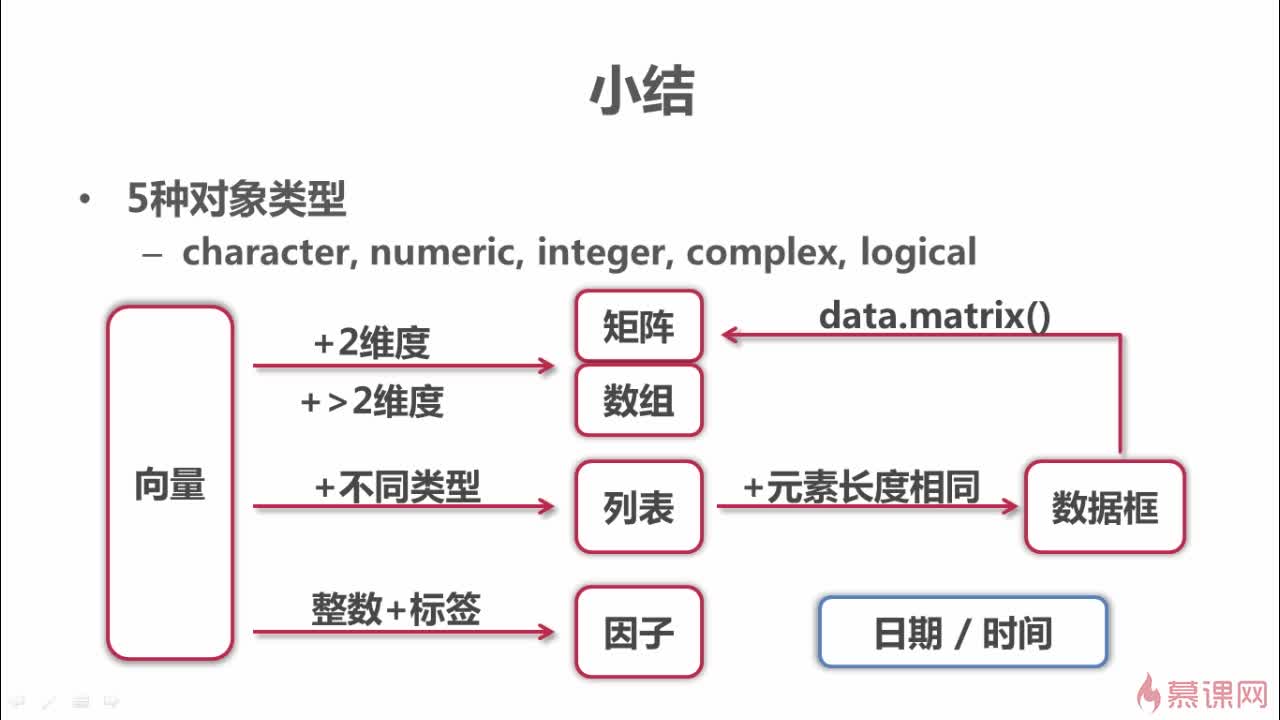
R语言的数据结构
对象的5中基本类型
- 字符character
- 数值numeric:real numbers
- 整型integer
- 复数complex:1+2i
- 逻辑logical:true/false
1.变量的赋值方式采用 <- 不要用 =
2.默认变量赋值类型为numeric数值型(包括小数和整数),如果欲强调整数,可在数据后加大写L。例如:x <- 5L
3.R中变量大小写敏感。查看变量类型的函数class(x)。查看变量值的方法(直接输入变量名称后回车)
4.字符串变量加双引。逻辑变量TRUE/FALSE全部大写
5.复数变量。例如:x <- 1+2i
向量
1.#是注释开始的标记
2.vector向量:支持自动扩容的数组
3.y <- vector(“character”,10) — 初始化长度为10的字符串数组
4.x <- 1:4 — x为1到4,含4个元素的数组
5.x2 <- c(1, 2, 3, 4) — 用列表方式初始化数组
6.x3 <- c(TRUE, 10, “a”) — 数组元素将被强制转换为同一类型
7.x4 <- c(“a”, “b”, “c”)
as.numeric(x4)
as.logical(x4)
as.character(x4) — 几种常用的强制转换方式(可能报错)
8.names(x1) <- c(“a”, “b”, “c”, “d”) — 为x1数组每个角标添加引用
矩阵与数组
1.矩阵定义:向量+维度属性
2.x <- matrix(nrow=3 ,ncol=2)#建立3行2列空矩阵
3.x <- matrix(1:6, nrow=3, ncol=2)#先列后行的方式初始化并建立3行2列矩阵
4.dim(x)#查看矩阵行列数
5.attributes(x)#查看矩阵属性及行列数(例如:维度属性:3行2列)
6.y <- 1:6
dim(y) <- c(2,3)#先建立向量,然后附加维度属性,使之成为矩阵。
y2 <- matrix(1:6, nrow=2, ncol=3)#建立一个和y相同的矩阵
rbind(y,y2)#将矩阵按行合并(行数增加,列数不变)
cbind(y,y2)#将矩阵按列合并(列数增加,行数不变)
数组
数组与矩阵相识,但数组可以是多维,矩阵只能是二维
创建数组 x<-array(1:24,dim=c(4,6))#array(内容,维度)
列表
列表(list):
1.列表与向量的差别:列表可以同时包含不同类型的对象
2.
l <- list(“a”, 2, 10L, 3+4i, TRUE)#建立列表
l2 <- list(a=1 ,b=2 ,c=3)#为列表元素命名
l3 <- list(c(1,2,3),c(4,5,6,7))#列表元素可以是向量,创建元素个数大于1
x <- matrix(1:6, nrow=2, ncol=3)
dimnames(x) <- list(c(“a”,”b”),c(“c”,”d”,”e”))#为矩阵维度(行、列)命名
因子(factor)
1.factor因子:因子=整数向量+标签
2.
x <- factor(c(“female”,”female”,”male”,”male”,”female”))
#设置基线水平
x <- factor(c(“female”,”female”,”male”,”male”,”female”),levels=c(“male”,”female”))#levels是因子的属性
3.table(x)#查看因子分类统计后的结果
4.unclass(x)#去掉标签,将因子变为整数向量(因子=整数变量+标签)
class(unclass(x))
缺失值(missing value)
- NA/NaN #NaN属于NA,NA不属于NaN(一般表示数字缺失值),前者包含后者,后者只表示数字的缺失。缺失值在数据预处理中很重要
- NA有类型属性:integer NA,character NA等
- is.na()/is.nan()#判断向量中是否有缺失值
数据框(data frame)
数据框在数据分析中经常被使用,用来存储表格数据(tabular data);
视为各元素长度相同的列表
*每个元素代表一列数据
*每个元素的长度代表行数
*元素类型可以不同
1.data fram数据框:同一列数据类型相同,且每一列长度相等
2.df <- data.frame(id=c(1,2,3),name=c(“a”,”b”,”c”),gender=c(“TRUE”,”TRUE”,”FALSE”)
3.nrow(df)#查看数据框行数
ncol(df)#查看数据框列数
4.data.matrix(df2)#数据转矩阵,元素是同种类型的
日期和时间
#Date
1.
x <- Date()#字符型
x2 <- Sys.Date()#Date型
x3 <- as.Date(“2016-01-01”)#创建Date型
- weekdays(x3)#星期几
months(x3)#月份
quarters(x3)#季度
3. julian(x3)#参数日期与1970-1-1相差几天
x3-x2#天数差含字符说明
as.numeric(x3-x2)#转换为数值
#Time
1.time创建与转换
CT类型与lt类型,前者是整数,后者以列表存在
x <- Sys.time()#POSIXct
p <- as.POSIXlt(x)#POSIXlt
as.POSIXct(p)#POSIXct
2.names(unclass(p))#p去掉属性,保留内容,查看POSIXl$t的属性
p$sec#获取p中指定属性的数据
3.x1 <- “一月 1, 2015 01:01”
strptime(x1, “%B %d, %Y %H:%M”)#字符串形式的时间格式化函数
数据操作
构建子集

x <- 1:10
x[1]#角标从1开始
x[1:5]#1到5的值
x[x>5]#大于5的值
x>5#返回的是逻辑向量,即每一个元素与5比较的逻辑值组成的向量
x[x>5 & x<7]#与
x[x<3 | x>7]#或
y < 1:4
names(y) <- c("a","b","c","d")
y["b"]#对于命名的向量,可以用列名代替角标
矩阵的子集
x <- matrix(1:6, nrow=2, ncol=3)
x[1,2]#返回指定坐标向量
x[1,]#返回指定行的向量
x[,2]#返回指定列的向量
x[1,c(1,3)]#返回指定行中特定列的向量
x[1,2]#返回向量
x[1,2,drop=FALSE]#返回矩阵,而不是向量
数据框的子集
x <- data.frame(v1=1:5, v2=6:10, v3=11:15)#数据框三列元素
x$v3[c(2,4)] <- NA#第三列第2、4个元素赋为缺失值
x[,"v2"]#与x[,2]等效
x[(x$v1<4 & x$v2>=8),]#条件获取
#以下两种方式在以后的学习中会辨析区别
x[x$v1>2,]
x[which(x$v1>2),]
x$v1>2#返回满足条件的逻辑向量
which(x$v1>2)#返回上述逻辑为真的数值向量
#条件构建子集的函数,此函数适用于矩阵,数据框等其他数据结构
subset(x,x$v1>2)
列表的子集
列表直接使用单括号不能拿能内容,而是名字和内容,所以用双括号
x <- list(id=1:4, height=170, gender="male")
x["id"]#与x[1]等效,返回的是名字和内容
#只返回内容
x[["id"]]
x$id
x[c(1,3)]#返回指定列
#可以用变量代替引用
y <- "id"
x[[y]]
#不可以用变量代替引用($)
x$id
x$y
#获取嵌套列表中的元素
x <- list(a=list(1,2,3,4),b=c("Monday","Tuesdat"))
x[[1]][[2]]#方法一:连续两个双括号
x[[c(1,3)]]#方法二:一个双括号,里面用c()函数
#不完全匹配
#如果一个不完全匹配有多个成功匹配,返回结果为NULL
l <- list(asdfghj=1:10)
l$asdfghj
l$a
l[["a",exact=FALSE]]#双括号关闭精确匹配
处理缺失值
x <- c(1, NA, 2, NA, 3)
x[!is.na(x)]#取得非缺失值
x <- c(1, NA, 2, NA, 3)
y <- c("a","b",NA,"c",NA)
z <- complete.cases(x,y)
x[z]
y[z]#取得两个向量中都不为NA的列
library(datasets)#导入R自带的数据集包
head(airquality)#head()方法查看数据集前几行
g <- complete.cases(airquality)
airquality[g,][1:10,]#显示前10条不含NA属性的记录
向量化操作
可以作用于向量,矩阵等结构,使得代码简洁,易于阅读,效率高
x<-1:5
y<-6:10
x+y x*y x/y
//创建两个矩阵
x<-matrix(1:4,nrow=2,ncol=2)
y<-matrix(rep(2,4)//把2重复4次,nrow=2,ncol=2)
x%*%y //矩阵乘法

R语言重要函数的使用
lapply函数
- lapply 可以循环处理列表中每一个元素
- lapply(参数):lapply(列表,函数/函数名,其他参数)
- 结果总是返回一个列表
str(lapply)
eg:
x<-list(a=1:10,b=c(11,21,31,41,51))
lapply(x,mean)#求平均
x<-1:4
lapply(x,runif)#runif,从一个均匀分布的总体里,抽取若干个数
lapply(x,runif,min=0,max=1000)
x<-list(a=matrix(1:6,2,3),b=matrix(4:7,2,2))
lapply(x,function(m) m[1,])
sapply//对lapply进行化简
结果列表长度均为1,返回向量
结果列表元素相同且大于1,返回矩阵
apply
#沿着数组的某一维度处理数据
#将函数用于矩阵的行或者列
#一句话就可以完成for/while函数
#apply(数组,维度,函数/函数名)
对于矩阵第一维度为行,第二维度为列
x <- matrix(1:16,4,4)
apply(x, 2, mean)#求列的平均
apply(x, 2, sum)#求列和
apply(x, 1, mean)#求行的平均
apply(x, 1, sum)#求行和
x <- matrix(rnorm(100),10,10) //rnorm随机从正态分布的数据中取出100个数据
apply(x, 1, quantile, probs = c(0.25, 0.75))
x <- array(rnorm(2*3*4),c(2,3,4))
apply(x,c(1,2), mean)
mapply
#lapply的多元版本
#mapply(参数)
#mapply(函数/函数名,数据, 函数相关的参数)
a<-list(rep(1,4), rep(2,3), rep(3,2),rep(4,1))
b<-mapply(rep,1:4,4:1)#等价于上面的list
s <- function(n, mean ,std){
rnorm(n, mean, std)
}
s(4,0,1)
#调用函数s,生成1到5四个元素,其中均值是5到1,标准差是2
mapply(s, 1:5,5:1,2)
list(s(1,5,2),s(2,4,2),s(3,3,2),s(4,2,2),s(5,1,2))#这个list的效果跟mapply函数一样
tapply
#对向量的子集进行操作
tapply(向量,因子/因子列表,函数/函数名)
x <- c(rnorm(5), runif(5),rnorm(5,1))
f <- gl(3,5)
tapply(x,f,mean)
tapply(x,f,mean, simplify = FALSE)
split
- 根据因子或者因子列表将向量或其他对象分组
- 通常与lapply一起使用
- 参数格式:split(向量/列表/数据框,因子/因子列表)
x <- c(rnorm(5), runif(5),rnorm(5,1))
f <- gl(3,5)
split(x,f)
lapply(split(x,f), mean)
lapply(split(x,f), sum)
head(airquality)
split(airquality,airquality$Month)#按照month分组查看
s <- split(airquality,airquality$Month)
table(airquality$Month)#查看每个Month下包含的记录数
lapply(s, function(x) colMeans(x[,c("Ozone","Wind","Temp")]))# 求平均值
sapply(s, function(x) colMeans(x[,c("Ozone","Wind","Temp")]))#简化显示结果
sapply(s, function(x) colMeans(x[,c("Ozone","Wind","Temp")],na.rm = T))#处理缺失值
排序
- sort对向量进行排序,返回排好序的内容
- order返回排好序的内容的下标
x <- data.frame(v1=1:5, v2=c(10,7,9,6,8), v3=11:15, v4=c(1,1,2,2,1))
x
sort(x$v2)#v2列按照升序排列
sort(x$v2,decreasing = True)#v2列按照降序排列
order(x$v2)#返回的不是内容本身,是内容的下标
x[order(x$v2),]#对x数据框按照v2进行排序
x[order(x$v4, x$v2, decreasing = True), ]#将序排列x,先按照v4,次要按照v2
总结数据信息
#默认前六行或者后六行
head(airquality, 10)#查看前10行
tail(airquality, 10)#查看后10行
summary(airquality)#总结,数据分布整体把握
str(airquality)#以简洁方式对数据总结
table(airquality$Month)#对列进行频数统计
table(airquality$Ozone, useNA = "ifany")#将Ozone中NA的数值统计出来
any(is.na(airquality$Ozone))#判断是否有缺失值,true是有缺失值
sum(is.na(airquality$Ozone))#统计缺失值数量
all(airquality$Month < 12)#查看是不是所有的月份都小于12
#将Titanic强制转换为数据框
t <- as.data.frame(Titanic)
x <- xtabs(Freq ~ Class + Age, data = t)#按照Class和Age生成交叉表
ftable(x)#扁平化显示
object.size(airquality)#查看对象大小
print(object.size(airquality),units="Kb")#按照kb显示大小
