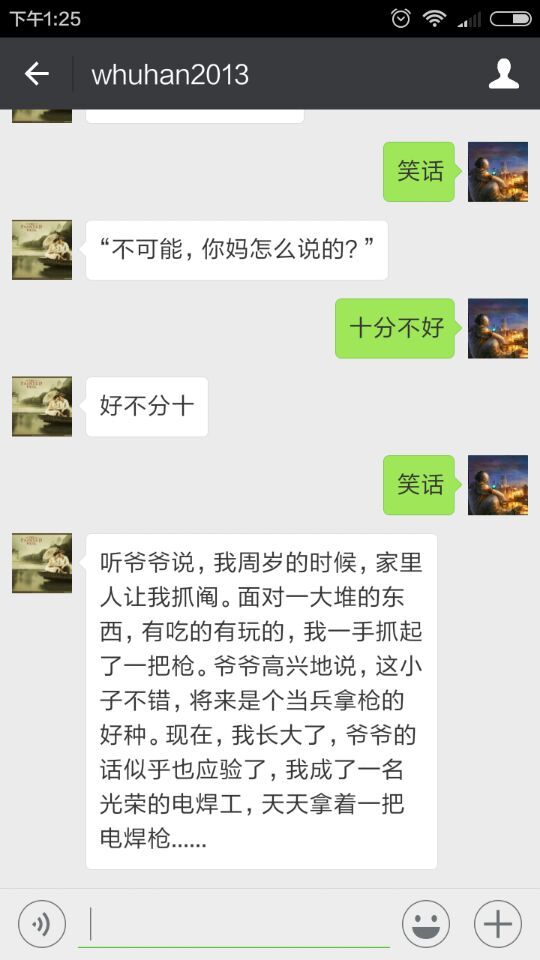
本文主要实现了以下功能
- 首先,肯定是正常运行,微信接口正常接入我们的服务器。
- 其次,当用户发送文字,我们可以倒序送回。
- 再者,只逆序回话,略显单调,额外添加一个讲笑话的功能,笑话内容通过爬虫获取。
主要包括以下知识点
- 微信公众平台参数配置
- Python 的编程基础
- Flask 的基本知识(看懂官网的几个小例子)
- Http 的基本知识(GET和POST请求,80端口)
- Web 服务网络知识
微信接口接入服务器
微信只开放80与443端口,分别与http与https对应
其中需要特殊注意加密/校验流程,如下:
- 将 token、timestamp、nonce 三个参数进行字典序排序
- 将三个参数字符串拼接成一个字符串进行 sha1 加密
- 开发者获得加密后的字符串可与 signature 对比,标识该请求来源于微信
微信的校验过程,是 GET 请求,所以三个参数都在 URL 中就能获取到,(另外 token 是在微信公众平台的配置页面自己配置的),校验流程的代码如下:
app = Flask(__name__)
@app.route('/',methods=['GET','POST'])
def wechat_auth():
if request.method == 'GET':
print('coming Get')
data = request.args
token = 'weixin'
signature = data.get('signature','')
timestamp = data.get('timestamp','')
nonce = data.get('nonce','')
echostr = data.get('echostr','')
s = [timestamp,nonce,token]
s.sort()
s = ''.join(s).encode("utf-8")
if (hashlib.sha1(s).hexdigest() == signature):
return make_response(echostr)
逆序输出与爬虫并返回笑话实现
Python 实现倒序输出
最简单的实现思路是使用 for 循环,申请同等大小的字符串,逆序赋值然后返回给服务器,但使用 Python 最方便的一点就是可以使用字符串的切片来实现逆序。
s[::-1] #这样就可以了,不填,默认全部咯,ok,完成了
实现爬虫
我们选择爬取的目标是糗事百科的纯文本内容,地址为糗事百科-纯文
if request.method == 'POST':
xml_str = request.stream.read()
xml = ET.fromstring(xml_str)
toUserName = xml.find('ToUserName').text
fromUserName = xml.find('FromUserName').text
createTime = xml.find('CreateTime').text
msgType = xml.find('MsgType').text
if msgType != 'text':
reply = '''
<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[%s]]></MsgType>
<Content><![CDATA[%s]]></Content>
</xml>
''' % (
fromUserName,
toUserName,
createTime,
'text',
'Unknow Format, Please check out'
)
return reply
content = xml.find('Content').text
msgId = xml.find('MsgId').text
if u'笑话' in content:
url="http://www.qiushibaike.com/text/"
print("here1")
r = requests.get(url)
tree = etree.HTML(r.text)
contentlist = tree.xpath('//div[@class="content"]/span/text()')
jokes = []
#print("here2",contentlist[0])
for i in contentlist:
contentstring = ''.join(i)
contentstring = contentstring.strip('\n')
jokes.append(contentstring)
#print("here3",jokes)
joke = jokes[randint(0, len(jokes))]
reply = '''
<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[%s]]></MsgType>
<Content><![CDATA[%s]]></Content>
</xml>
''' % (fromUserName, toUserName, createTime, msgType, joke)
return reply
else:
if type(content).__name__ == "unicode":
content = content[::-1]
content = content.encode('UTF-8')
elif type(content).__name__ == "str":
print(type(content).__name__)
content = content
content = content[::-1]
reply = '''
<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[%s]]></MsgType>
<Content><![CDATA[%s]]></Content>
</xml>
''' % (fromUserName, toUserName, createTime, msgType, content)
return reply
源码地址:微信机器人
参考链接
Python - 基于 Flask 及爬虫实现微信娱乐机器人 - 实验楼
效果如下