原型模式概念
原型模式(Prototype Pattern):使用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。原型模式是一种对象创建型模式。
该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
需要注意的是通过克隆方法所创建的对象是全新的对象,它们在内存中拥有新的地址,通常对克隆所产生的对象进行修改对原型对象不会造成任何影响,每一个克隆对象都是相互独立的。通过不同的方式修改可以得到一系列相似但不完全相同的对象。
原型模式结构图
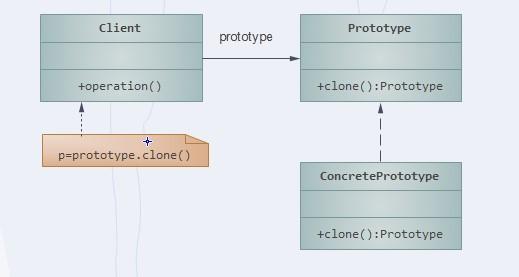
在原型模式结构图中包含如下几个角色:
- 抽象原型角色(Prototype):它是声明克隆方法的接口,是所有具体原型类的公共父类,可以是抽象类也可以是接口,甚至还可以是具体实现类。
- 具体原型角色(ConcretePrototype):它实现在抽象原型类中声明的克隆方法,在克隆方法中返回自己的一个克隆对象。
- 客户角色(Client):客户类提出创建对象的请求。
原型模式的核心在于如何实现克隆方法,博主本人是从事Java开发,所以用Java语言提供的clone()方法来实现。学过Java语言的人都知道,所有的Java类都继承自java.lang.Object。事实上,Object类提供一个clone()方法,可以将一个Java对象复制一份。因此在Java中可以直接使用Object提供的clone()方法来实现对象的克隆,Java语言中的原型模式实现很简单。
需要注意的是能够实现克隆的Java类必须实现一个标识接口Cloneable,表示这个Java类支持被复制。如果一个类没有实现这个接口但是调用了clone()方法,Java编译器将抛出一个CloneNotSupportedException异常。
克隆满足的条件
clone()方法将对象复制了一份并返还给调用者。所谓“复制”的含义与clone()方法是怎么实现的有关。一般而言,clone()方法满足以下的描述:
- 对任何的对象x,都有:x.clone()!=x 。换言之,克隆对象与元对象不是一个对象。
- 对任何的对象x,都有:x.clone().getClass==x.getClass(),换言之,克隆对象与元对象的类型一样。
- 如果对象x的equals()方法定于恰当的话,那么x.clone().equals(x)应当是成立的。
在Java语言的API中,凡是提供了clone()方法的类,都满足上面的这些条件。Java语言的设计师在设计自己的clone()方法时,也应当遵守这三个条件。
在理解Java原型模式之前,首先需要理解Java中的一个概念:复制/克隆。Java中的对象复制/克隆分为浅复制和深复制。在Java语言中,数据类型分为值类型(基本数据类型)和引用类型,值类型包括int、double、byte、boolean、char等简单数据类型,引用类型包括类、接口、数组等复杂类型。浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制,下面将对两者进行详细介绍。
浅克隆
在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。简单来说,在浅克隆中,当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制。
深克隆
在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。简单来说,在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
在Java语言中,如果需要实现深克隆,可以通过序列化(Serialization)等方式来实现。序列化就是将对象写到流的过程,写到流中的对象是原有对象的一个拷贝,而原对象仍然存在于内存中。通过序列化实现的拷贝不仅可以复制对象本身,而且可以复制其引用的成员对象,因此通过序列化将对象写到一个流中,再从流里将其读出来,可以实现深克隆。需要注意的是能够实现序列化的对象其类必须实现Serializable接口,否则无法实现序列化操作。
深复制不仅在堆内存上开辟了空间以存储复制出的对象,甚至连对象中的引用类型的属性所指向的对象也得以复制,重新开辟了堆空间存储。
总结
原型模式作为一种快速创建大量相同或相似对象的方式,在软件开发中应用较为广泛,很多软件提供的复制(Ctrl + C)和粘贴(Ctrl + V)操作就是原型模式的典型应用,下面对该模式的使用效果和适用情况进行简单的总结。
1.主要优点
原型模式的主要优点如下:
当创建新的对象实例较为复杂时,使用原型模式可以简化对象的创建过程,通过复制一个已有实例可以提高新实例的创建效率。 扩展性较好,由于在原型模式中提供了抽象原型类,在客户端可以针对抽象原型类进行编程,而将具体原型类写在配置文件中,增加或减少产品类对原有系统都没有任何影响。
原型模式提供了简化的创建结构,工厂方法模式常常需要有一个与产品类等级结构相同的工厂等级结构,而原型模式就不需要这样,原型模式中产品的复制是通过封装在原型类中的克隆方法实现的,无须专门的工厂类来创建产品。 可以使用深克隆的方式保存对象的状态,使用原型模式将对象复制一份并将其状态保存起来,以便在需要的时候使用(如恢复到某一历史状态),可辅助实现撤销操作。
2.主要缺点
原型模式的主要缺点如下:
需要为每一个类配备一个克隆方法,而且该克隆方法位于一个类的内部,当对已有的类进行改造时,需要修改源代码,违背了“开闭原则”。
在实现深克隆时需要编写较为复杂的代码,而且当对象之间存在多重的嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来可能会比较麻烦。
3.适用场景
在以下情况下可以考虑使用原型模式:
创建新对象成本较大(如初始化需要占用较长的时间,占用太多的CPU资源或网络资源),新的对象可以通过原型模式对已有对象进行复制来获得,如果是相似对象,则可以对其成员变量稍作修改。 如果系统要保存对象的状态,而对象的状态变化很小,或者对象本身占用内存较少时,可以使用原型模式配合备忘录模式来实现。 需要避免使用分层次的工厂类来创建分层次的对象,并且类的实例对象只有一个或很少的几个组合状态,通过复制原型对象得到新实例可能比使用构造函数创建一个新实例更加方便。