在上一节定义了从图像像素值到所属类别的评分函数(score function),该函数的参数是权重矩阵$W_i$。在函数中,数据$(x_i,y_i)$是给定的,不能修改。但是我们可以调整权重矩阵这个参数,使得评分函数的结果与训练数据集中图像的真实类别一致,即评分函数在正确的分类的位置应当得到最高的评分(score)
回到之前那张猫的图像分类例子,它有针对“猫”,“狗”,“船”三个类别的分数。我们看到例子中权重值非常差,因为猫分类的得分非常低(-96.8),而狗(437.9)和船(61.95)比较高。我们将使用损失函数(Loss Function)(有时也叫代价函数Cost Function或目标函数Objective)来衡量我们对结果的不满意程度。直观地讲,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
多类支持向量机损失 Multiclass Support Vector Machine Loss
损失函数的具体形式多种多样。首先,介绍常用的多类支持向量机(SVM)损失函数。SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值。我们可以把损失函数想象成一个人,这位SVM先生(或者女士)对于结果有自己的品位,如果某个结果能使得损失值更低,那么SVM就更加喜欢它。

可以看到第一个部分结果是0,这是因为[-7-13+10]得到的是负数,经过函数处理后得到0。这一对类别分数和标签的损失值是0,这是因为正确分类的得分13与错误分类的得分-7的差为20,高于边界值10。而SVM只关心差距至少要大于10,更大的差值还是算作损失值为0。第二个部分计算[11-13+10]得到8。虽然正确分类的得分比不正确分类的得分要高(13>11),但是比10的边界值还是小了,分差只有2,这就是为什么损失值等于8。简而言之,SVM的损失函数想要正确分类类别$y_i$的分数比不正确类别分数高,而且至少要高$\delta$。如果不满足这点,就开始计算损失值。

在结束这一小节前,还必须提一下的属于是关于0的阀值:$max(0,-)$函数,它常被称为折叶损失(hinge loss)。有时候会听到人们使用平方折叶损失SVM(即L2-SVM),它使用的是$max(0,-)^2$,将更强烈(平方地而不是线性地)地惩罚过界的边界值。不使用平方是更标准的版本,但是在某些数据集中,平方折叶损失会工作得更好。可以通过交叉验证来决定到底使用哪个。
我们对于预测训练集数据分类标签的情况总有一些不满意的,而损失函数就能将这些不满意的程度量化。

多类SVM“想要”正确类别的分类分数比其他不正确分类类别的分数要高,而且至少高出delta的边界值。如果其他分类分数进入了红色的区域,甚至更高,那么就开始计算损失。如果没有这些情况,损失值为0。我们的目标是找到一些权重,它们既能够让训练集中的数据样例满足这些限制,也能让总的损失值尽可能地低。
正则化(Regularization)
上面损失函数有一个问题。假设有一个数据集和一个权重集W能够正确地分类每个数据(即所有的边界都满足,对于所有的i都有$L_i=0$)。问题在于这个W并不唯一:可能有很多相似的W都能正确地分类所有的数据。一个简单的例子:如果W能够正确分类所有数据,即对于每个数据,损失值都是0。那么当$\lambda$时,任何数乘$\lambda$W都能使得损失值为0,因为这个变化将所有分值的大小都均等地扩大了,所以它们之间的绝对差值也扩大了。举个例子,如果一个正确分类的分值和举例它最近的错误分类的分值的差距是15,对W乘以2将使得差距变成30。
换句话说,我们希望能向某些特定的权重W添加一些偏好,对其他权重则不添加,以此来消除模糊性。这一点是能够实现的,方法是向损失函数增加一个正则化惩罚(regularization penalty)部分。最常用的正则化惩罚是L2范式,L2范式通过对所有参数进行逐元素的平方惩罚来抑制大数值的权重:
\[R(W)=\sum_k\sum_l{W_{k,l}^2}\]
其中,N是训练集的数据量。现在正则化惩罚添加到了损失函数里面,并用超参数$\lambda$来计算其权重。该超参数无法简单确定,需要通过交叉验证来获取。
除了上述理由外,引入正则化惩罚还带来很多良好的性质,这些性质大多会在后续章节介绍。比如引入了L2惩罚后,SVM们就有了最大边界(max margin)这一良好性质。
其中最好的性质就是对大数值权重进行惩罚,可以提升其泛化能力,因为这就意味着没有哪个维度能够独自对于整体分值有过大的影响。
需要注意的是,和权重不同,偏差没有这样的效果,因为它们并不控制输入维度上的影响强度。因此通常只对权重正则化,而不正则化偏差。在实际操作中,可发现这一操作的影响可忽略不计。最后,因为正则化惩罚的存在,不可能在所有的例子中得到0的损失值,这是因为只有当的特殊情况下,才能得到损失值为0。
代码:下面是一个无正则化部分的损失函数的Python实现,有非向量化和半向量化两个形式:
def L_i(x, y, W):
"""
unvectorized version. Compute the multiclass svm loss for a single example (x,y)
- x is a column vector representing an image (e.g. 3073 x 1 in CIFAR-10)
with an appended bias dimension in the 3073-rd position (i.e. bias trick)
- y is an integer giving index of correct class (e.g. between 0 and 9 in CIFAR-10)
- W is the weight matrix (e.g. 10 x 3073 in CIFAR-10)
"""
delta = 1.0 # see notes about delta later in this section
scores = W.dot(x) # scores becomes of size 10 x 1, the scores for each class
correct_class_score = scores[y]
D = W.shape[0] # number of classes, e.g. 10
loss_i = 0.0
for j in xrange(D): # iterate over all wrong classes
if j == y:
# skip for the true class to only loop over incorrect classes
continue
# accumulate loss for the i-th example
loss_i += max(0, scores[j] - correct_class_score + delta)
return loss_i
def L_i_vectorized(x, y, W):
"""
A faster half-vectorized implementation. half-vectorized
refers to the fact that for a single example the implementation contains
no for loops, but there is still one loop over the examples (outside this function)
"""
delta = 1.0
scores = W.dot(x)
# compute the margins for all classes in one vector operation
margins = np.maximum(0, scores - scores[y] + delta)
# on y-th position scores[y] - scores[y] canceled and gave delta. We want
# to ignore the y-th position and only consider margin on max wrong class
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
def L(X, y, W):
"""
fully-vectorized implementation :
- X holds all the training examples as columns (e.g. 3073 x 50,000 in CIFAR-10)
- y is array of integers specifying correct class (e.g. 50,000-D array)
- W are weights (e.g. 10 x 3073)
"""
# evaluate loss over all examples in X without using any for loops
# left as exercise to reader in the assignment
实际考虑

Softmax分类器
SVM是最常用的两个分类器之一,而另一个就是Softmax分类器,它的损失函数与SVM的损失函数不同。对于学习过二元逻辑回归分类器的读者来说,Softmax分类器就可以理解为逻辑回归分类器面对多个分类的一般化归纳。SVM将输出$f(x_i,W)$作为每个分类的评分(因为无定标,所以难以直接解释)。与SVM不同,Softmax的输出(归一化的分类概率)更加直观,并且从概率上可以解释,这一点后文会讨论。在Softmax分类器中,函数$f(x_i;W)=Wx_i$映射保持不变,但将这些评分值视为每个分类的未归一化的对数概率,并且将折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss)。公式如下:


可以解释为是给定图像数据$x_i$,以W为参数,分配给正确分类标签的归一化概率。为了理解这点,请回忆一下Softmax分类器将输出向量中的评分值解释为没有归一化的对数概率。那么以这些数值做指数函数的幂就得到了没有归一化的概率,而除法操作则对数据进行了归一化处理,使得这些概率的和为1。从概率论的角度来理解,我们就是在最小化正确分类的负对数概率,这可以看做是在进行最大似然估计(MLE)。该解释的另一个好处是,损失函数中的正则化部分R(W)可以被看做是权重矩阵的高斯先验,这里进行的是最大后验估计(MAP)而不是最大似然估计。提及这些解释只是为了让读者形成直观的印象,具体细节就超过本课程范围了。

其实可以看做给定图片数据xi和类别yi以及参数W之后的归一化概率。在概率的角度理解,我们在做的事情,就是最小化错误类别的负log似然概率,也可以理解为进行最大似然估计/Maximum Likelihood Estimation (MLE)。这个理解角度还有一个好处,这个时候我们的正则化项R(W)有很好的解释性,可以理解为整个损失函数在权重矩阵W上的一个高斯先验,所以其实这时候是在做一个最大后验估计/Maximum a posteriori (MAP)。

f = np.array([123, 456, 789]) # 例子中有3个分类,每个评分的数值都很大
p = np.exp(f) / np.sum(np.exp(f)) # 不妙:数值问题,可能导致数值爆炸
# 那么将f中的值平移到最大值为0:
f -= np.max(f) # f becomes [-666, -333, 0]
p = np.exp(f) / np.sum(np.exp(f)) # 现在OK了,将给出正确结果
关于softmax这个名字的一点说明
精确地说,SVM分类器使用的是折叶损失(hinge loss),有时候又被称为最大边界损失(max-margin loss)。Softmax分类器使用的是交叉熵损失(corss-entropy loss)。Softmax分类器的命名是从softmax函数那里得来的,softmax函数将原始分类评分变成正的归一化数值,所有数值和为1,这样处理后交叉熵损失才能应用。注意从技术上说“softmax损失(softmax loss)”是没有意义的,因为softmax只是一个压缩数值的函数。但是在这个说法常常被用来做简称。
SVM和Softmax的比较
下图有助于区分这 Softmax和SVM这两种分类器:
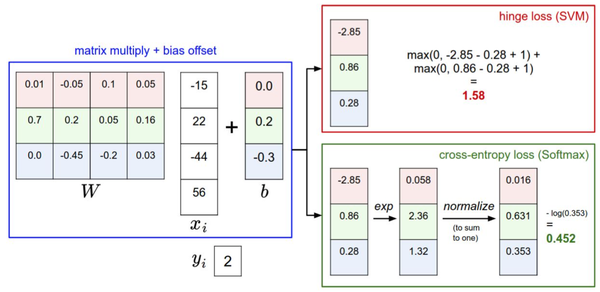
针对一个数据点,SVM和Softmax分类器的不同处理方式的例子。两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
- SVM下,我们能完成类别的判定,但是实际上我们得到的类别得分,大小顺序表示着所属类别的排序,但是得分的绝对值大小并没有特别明显的物理含义。
- Softmax分类器中,结果的绝对值大小表征属于该类别的概率。
举个例子说,SVM可能拿到对应 猫/狗/船 的得分[12.5, 0.6, -23.0],同一个问题,Softmax分类器拿到[0.9, 0.09, 0.01]。这样在SVM结果下我们只知道『猫』是正确答案,而在Softmax分类器的结果中,我们可以知道属于每个类别的概率。
但是,Softmax中拿到的概率,其实和正则化参数λ有很大的关系,因为λ实际上在控制着W的伸缩程度,所以也控制着最后得分的scale,这会直接影响最后概率向量中概率的『分散度』,比如说某个λ下,我们得到的得分和概率可能如下:

现在看起来,概率的分布就更加分散了。还有,随着正则化参数λ不断增强,权重数值会越来越小,最后输出的概率会接近于均匀分布。这就是说,softmax分类器算出来的概率最好是看成一种对于分类正确性的自信。和SVM一样,数字间相互比较得出的大小顺序是可以解释的,但其绝对值则难以直观解释。
实际应用中的SVM与Softmax分类器
SVM其实并不在乎每个类别得到的绝对得分大小,举个例子说,我们现在对三个类别,算得的得分是[10, -2, 3],实际第一类是正确结果,而设定Δ=1,那么10-3=7已经比1要大很多了,那对SVM而言,它觉得这已经是一个很标准的答案了,完全满足要求了,不需要再做其他事情了,结果是 [10, -100, -100] 或者 [10, 9, 9],它都是满意的。
然而对于Softmax而言,不是这样的, [10, -100, -100] 和 [10, 9, 9]映射到概率域,计算得到的互熵损失是有很大差别的。所以Softmax是一个永远不会满足的分类器,在每个得分计算到的概率基础上,它总是觉得可以让概率分布更接近标准结果一些,互熵损失更小一些。