概述
Artificial Intelligence,也就是人工智能,就像长生不老和星际漫游一样,是人类最美好的梦想之一。虽然计算机技术已经取得了长足的进步,但是到目前为止,还没有一台电脑能产生“自我”的意识。是的,在人类和大量现成数据的帮助下,电脑可以表现的十分强大,但是离开了这两者,它甚至都不能分辨一个喵星人和一个汪星人。
图灵(图灵,大家都知道吧。计算机和人工智能的鼻祖,分别对应于其著名的“图灵机”和“图灵测试”)在 1950 年的论文里,提出图灵试验的设想,即,隔墙对话,你将不知道与你谈话的,是人还是电脑。这无疑给计算机,尤其是人工智能,预设了一个很高的期望值。但是半个世纪过去了,人工智能的进展,远远没有达到图灵试验的标准。这不仅让多年翘首以待的人们,心灰意冷,认为人工智能是忽悠,相关领域是“伪科学”。
但是自 2006 年以来,机器学习领域,取得了突破性的进展。图灵试验,至少不是那么可望而不可及了。至于技术手段,不仅仅依赖于云计算对大数据的并行处理能力,而且依赖于算法。这个算法就是,Deep Learning。借助于 Deep Learning 算法,人类终于找到了如何处理“抽象概念”这个亘古难题的方法。
背景
机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。机器能否像人类一样能具有学习能力呢?1959年美国的塞缪尔(Samuel)设计了一个下棋程序,这个程序具有学习能力,它可以在不断的对弈中改善自己的棋艺。4年后,这个程序战胜了设计者本人。又过了3年,这个程序战胜了美国一个保持8年之久的常胜不败的冠军。
机器学习虽然发展了几十年,但还是存在很多没有良好解决的问题:
例如图像识别、语音识别、自然语言理解、天气预测、基因表达、内容推荐等等。目前我们通过机器学习去解决这些问题的思路都是这样的(以视觉感知为例子):

在深度学习算法出来之前,对于视觉算法来说,大致可以分为以下5个步骤:特征感知,图像预处理,特征提取,特征筛选,推理预测与识别。早期的机器学习中,占优势的统计机器学习群体中,对特征是不大关心的。我认为,计算机视觉可以说是机器学习在视觉领域的应用,所以计算机视觉在采用这些机器学习方法的时候,不得不自己设计前面4个部分。 但对任何人来说这都是一个比较难的任务。传统的计算机识别方法把特征提取和分类器设计分开来做,然后在应用时再合在一起,比如如果输入是一个摩托车图像的话,首先要有一个特征表达或者特征提取的过程,然后把表达出来的特征放到学习算法中进行分类的学习。

截止现在,也出现了不少NB的特征(好的特征应具有不变性(大小、尺度和旋转等)和可区分性):例如Sift的出现,是局部图像特征描述子研究领域一项里程碑式的工作。由于SIFT对尺度、旋转以及一定视角和光照变化等图像变化都具有不变性,并且SIFT具有很强的可区分性,的确让很多问题的解决变为可能。但它也不是万能的。

然而,手工地选取特征是一件非常费力、启发式(需要专业知识)的方法,能不能选取好很大程度上靠经验和运气,而且它的调节需要大量的时间。既然手工选取特征不太好,那么能不能自动地学习一些特征呢?答案是能!Deep Learning就是用来干这个事情的,看它的一个别名UnsupervisedFeature Learning,就可以顾名思义了,Unsupervised的意思就是不要人参与特征的选取过程。
仿生学角度看深度学习
如果不手动设计特征,不挑选分类器,有没有别的方案呢?能不能同时学习特征和分类器?即输入某一个模型的时候,输入只是图片,输出就是它自己的标签。比如输入一个明星的头像,出来的标签就是一个50维的向量(如果要在50个人里识别的话),其中对应明星的向量是1,其他的位置是0
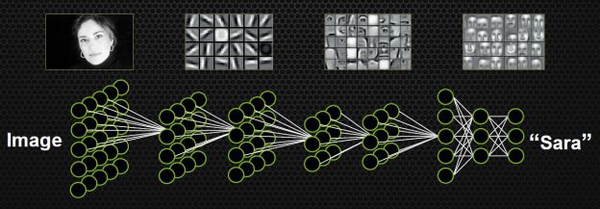
这种设定符合人类脑科学的研究成果。1981年诺贝尔医学生理学奖颁发给了David Hubel,一位神经生物学家。他的主要研究成果是发现了视觉系统信息处理机制,证明大脑的可视皮层是分级的。他的贡献主要有两个,一是他认为人的视觉功能一个是抽象,一个是迭代。抽象就是把非常具体的形象的元素,即原始的光线像素等信息,抽象出来形成有意义的概念。这些有意义的概念又会往上迭代,变成更加抽象,人可以感知到的抽象概念。像素是没有抽象意义的,但人脑可以把这些像素连接成边缘,边缘相对像素来说就变成了比较抽象的概念;边缘进而形成球形,球形然后到气球,又是一个抽象的过程,大脑最终就知道看到的是一个气球

模拟人脑识别人脸,也是抽象迭代的过程,从最开始的像素到第二层的边缘,再到人脸的部分,然后到整张人脸,是一个抽象迭代的过程。
再比如看到图片中的摩托车,我们可能在脑子里就几微秒的时间,但是经过了大量的神经元抽象迭代。对计算机来说最开始看到的根本也不是摩托车,而是RGB图像三个通道上不同的数字。所谓的特征或者视觉特征,就是把这些数值给综合起来用统计或非统计的形式,把摩托车的部件或者整辆摩托车表现出来。深度学习的流行之前,大部分的设计图像特征就是基于此,即把一个区域内的像素级别的信息综合表现出来,利于后面的分类学习。如果要完全模拟人脑,我们也要模拟抽象和递归迭代的过程,把信息从最细琐的像素级别,抽象到“种类”的概念,让人能够接受。
总的来说,人的视觉系统的信息处理是分级的。从低级的V1区提取边缘特征,再到V2区的形状或者目标的部分等,再到更高层,整个目标、目标的行为等。也就是说高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图。而抽象层面越高,存在的可能猜测就越少,就越利于分类。例如,单词集合和句子的对应是多对一的,句子和语义的对应又是多对一的,语义和意图的对应还是多对一的,这是个层级体系。
卷积的概念
计算机视觉里经常使卷积神经网络,即CNN,是一种对人脑比较精准的模拟。
什么是卷积?卷积就是两个函数之间的相互关系,然后得出一个新的值,他是在连续空间做积分计算,然后在离散空间内求和的过程。实际上在计算机视觉里面,可以把卷积当做一个抽象的过程,就是把小区域内的信息统计抽象出来。
比如,对于一张爱因斯坦的照片,我可以学习n个不同的卷积和函数,然后对这个区域进行统计。可以用不同的方法统计,比如着重统计中央,也可以着重统计周围,这就导致统计的和函数的种类多种多样,为了达到可以同时学习多个统计的累积和。
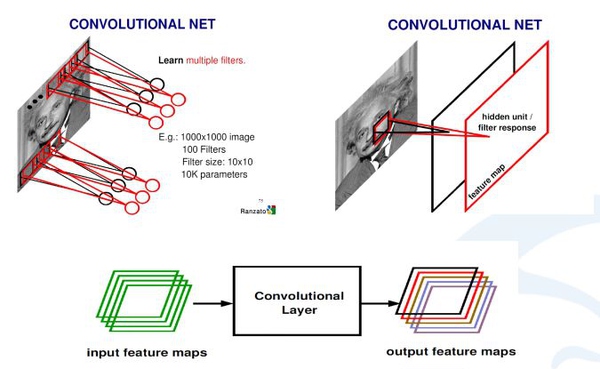
上图中是,如何从输入图像怎么到最后的卷积,生成的响应map。首先用学习好的卷积和对图像进行扫描,然后每一个卷积和会生成一个扫描的响应图,我们叫response map,或者叫feature map。如果有多个卷积和,就有多个feature map。也就说从一个最开始的输入图像(RGB三个通道)可以得到256个通道的feature map,因为有256个卷积和,每个卷积和代表一种统计抽象的方式。
在卷积神经网络中,除了卷积层,还有一种叫池化的操作。池化操作在统计上的概念更明确,就是一个对一个小区域内求平均值或者求最大值的统计操作。带来的结果是,如果之前我输入有两个通道的,或者256通道的卷积的响应feature map,每一个feature map都经过一个求最大的一个池化层,会得到一个比原来feature map更小的256的feature map。
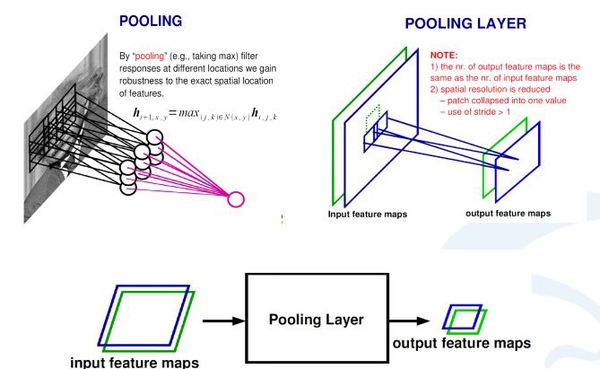
在上面这个例子里,池化层对每一个2X2的区域求最大值,然后把最大值赋给生成的feature map的对应位置。如果输入图像是100×100的话,那输出图像就会变成50×50,feature map变成了一半。同时保留的信息是原来2X2区域里面最大的信息。
参考文献
Deep Learning(深度学习)学习笔记整理系列之(一)