车牌定位实现过程
plateLocate的总体识别思路是:如果我们的车牌没有大的旋转或变形,那么其中必然包括很多垂直边缘(这些垂直边缘往往缘由车牌中的字符),如果能够找到一个包含很多垂直边缘的矩形块,那么有很大的可能性它就是车牌。
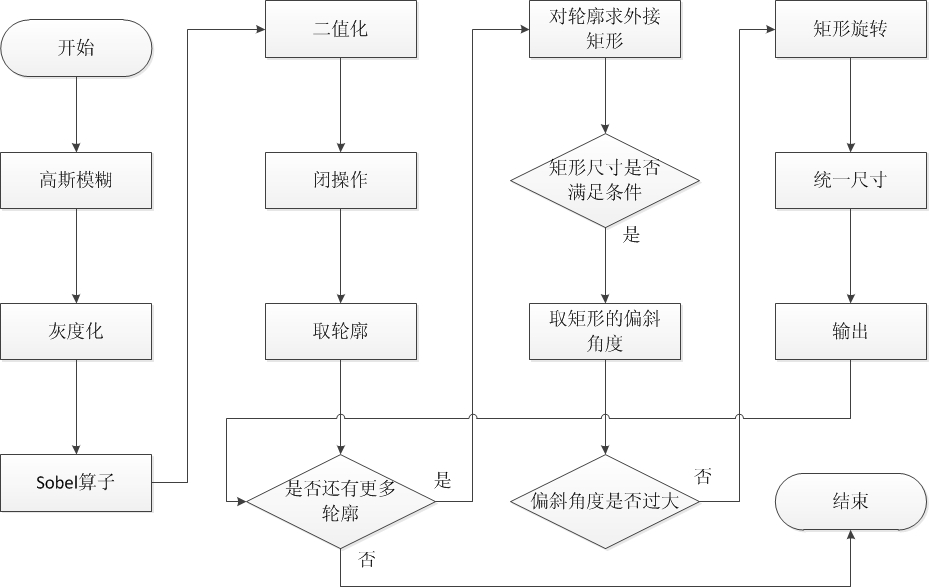
主要步骤
1、高斯模糊
2、经过高斯模糊后的图片。经过这步处理,可以看出图像变的模糊了。这步的作用是为接下来的Sobel算子去除干扰的噪声。
3、将图像进行灰度化。这个步骤是一个分水岭,意味着后面的所有操作都不能基于色彩信息了。
4、对图像进行Sobel运算,得到的是图像的一阶水平方向导数。这步过后,车牌被明显的区分出来。
5、对图像进行二值化。将灰度图像(每个像素点有256个取值可能)转化为二值图像(每个像素点仅有1和0两个取值可能)。
6、使用闭操作。对图像进行闭操作以后,可以看到车牌区域被连接成一个矩形装的区域。
7、求轮廓。求出图中所有的轮廓。这个算法会把全图的轮廓都计算出来,因此要进行筛选。
8、筛选。对轮廓求最小外接矩形,然后验证,不满足条件的淘汰。
9、角度判断与旋转。把倾斜角度大于阈值(如正负30度)的矩形舍弃。余下的矩形进行微小的旋转,使其水平。
10、统一尺寸。上步得到的图块尺寸是不一样的。为了进入机器学习模型,需要统一尺寸。统一尺寸的标准宽度是136,长度是36。这个标准是对千个测试车牌平均后得出的通用值。
这些“车牌”有两个作用:一、积累下来作为支持向量机(SVM)模型的训练集,以此训练出一个车牌判断模型;二、在实际的车牌检测过程中,将这些候选“车牌”交由训练好的车牌判断模型进行判断。如果车牌判断模型认为这是车牌的话就进入下一步即字符识别过程,如果不是,则舍弃。
车牌定位头文件
class CPlateLocate
{
public:
CPlateLocate();
//! 车牌定位
int plateLocate(Mat, vector<Mat>& );
//! 车牌的尺寸验证
bool verifySizes(RotatedRect mr);
//! 结果车牌显示
Mat showResultMat(Mat src, Size rect_size, Point2f center);
//! 设置与读取变量
//...
protected:
//! 高斯模糊所用变量
int m_GaussianBlurSize;
//! 连接操作所用变量
int m_MorphSizeWidth;
int m_MorphSizeHeight;
//! verifySize所用变量
float m_error;
float m_aspect;
int m_verifyMin;
int m_verifyMax;
//! 角度判断所用变量
int m_angle;
//! 是否开启调试模式,0关闭,非0开启
int m_debug;
};
原图像

高斯模糊
在数次的实验以后,必须承认,保留高斯模糊过程与半径值为5是最佳的实践。为应对特殊需求,在CPlateLocate类中也应该提供了方法修改高斯半径的值,调用代码如下:
GaussianBlur( src, out, Size( getM_GaussianBlurSize(), getM_GaussianBlurSize() ), 0, 0 );

灰度化处理
在灰度化处理步骤中,争议最大的就是信息的损失。无疑的,原先plateLocate过程面对的图片是彩色图片,而从这一步以后,就会面对的是灰度图片。在前面,已经说过这步骤是利是弊是需要讨论的。
无疑,对于计算机而言,色彩图像相对于灰度图像难处理多了,很多图像处理算法仅仅只适用于灰度图像,例如后面提到的Sobel算子。在这种情况下,你除 了把图片转成灰度图像再进行处理别无它法,除非重新设计算法。但另一方面,转化成灰度图像后恰恰失去了最丰富的细节。要知道,真实世界是彩色的,人类对于 事物的辨别是基于彩色的框架。甚至可以这样说,因为我们的肉眼能够区别彩色,所以我们对于事物的区分,辨别,记忆的能力就非常的强。
车牌定位环节中去掉彩色的利弊也是同理。转换成灰度图像虽然利于使用各种专用的算法,但失去了真实世界中辨别的最重要工具—色彩的区分。举个简单的例 子,人怎么在一张图片中找到车牌?非常简单,一眼望去,一个合适大小的矩形,蓝色的、或者黄色的、或者其他颜色的在另一个黑色,或者白色的大的跟车形类似 的矩形中。这个过程非常直观,明显,而且可以排除模糊,色泽,不清楚等很多影响。如果使用灰度图像,就必须借助水平,垂直求导等方法。
灰度化实现如下,调用代码:
cvtColor( out, out, CV_RGB2GRAY );

Sobel算子
检测图像中的垂直边缘,便于区分车牌。
如果要说哪个步骤是plateLocate中的核心与灵魂,毫无疑问是Sobel算子。没有Sobel算子,也就没有垂直边缘的检测,也就无法得到车牌 的可能位置,也就没有后面的一系列的车牌判断、字符识别过程。通过Sobel算子,可以很方便的得到车牌的一个相对准确的位置,为我们的后续处理打好坚实 的基础。在上面的plateLocate的执行过程中可以看到,正是通过Sobel算子,将车牌中的字符与车的背景明显区分开来,为后面的二值化与闭操作 打下了基础
Mat grad_x, grad_y;
Mat abs_grad_x, abs_grad_y;
Mat dst;
Sobel( out, grad_x, CV_16S, 1, 0, 3, 1, 0, BORDER_DEFAULT );
convertScaleAbs( grad_x, abs_grad_x );
Sobel( out, grad_y, CV_16S, 0, 1, 3, 1, 0, BORDER_DEFAULT );
convertScaleAbs( grad_y, abs_grad_y );
addWeighted( abs_grad_x, 1, abs_grad_y, 0, 0, dst);
Sobel算子求图像的一阶导数,Laplace算子则是求图像的二阶导数,在通常情况下,也能检测出边缘,不过Laplace算子的检测不分水平和垂直。我们只要垂直边缘,所以放弃更加精确的边缘检测算法,在sobel算子中也将垂直算子的权重设为0.
有一点要说明的:Sobel算子仅能对灰度图像有效果,不能将色彩图像作为输入。因此在进行Soble算子前必须进行前面的灰度化工作。

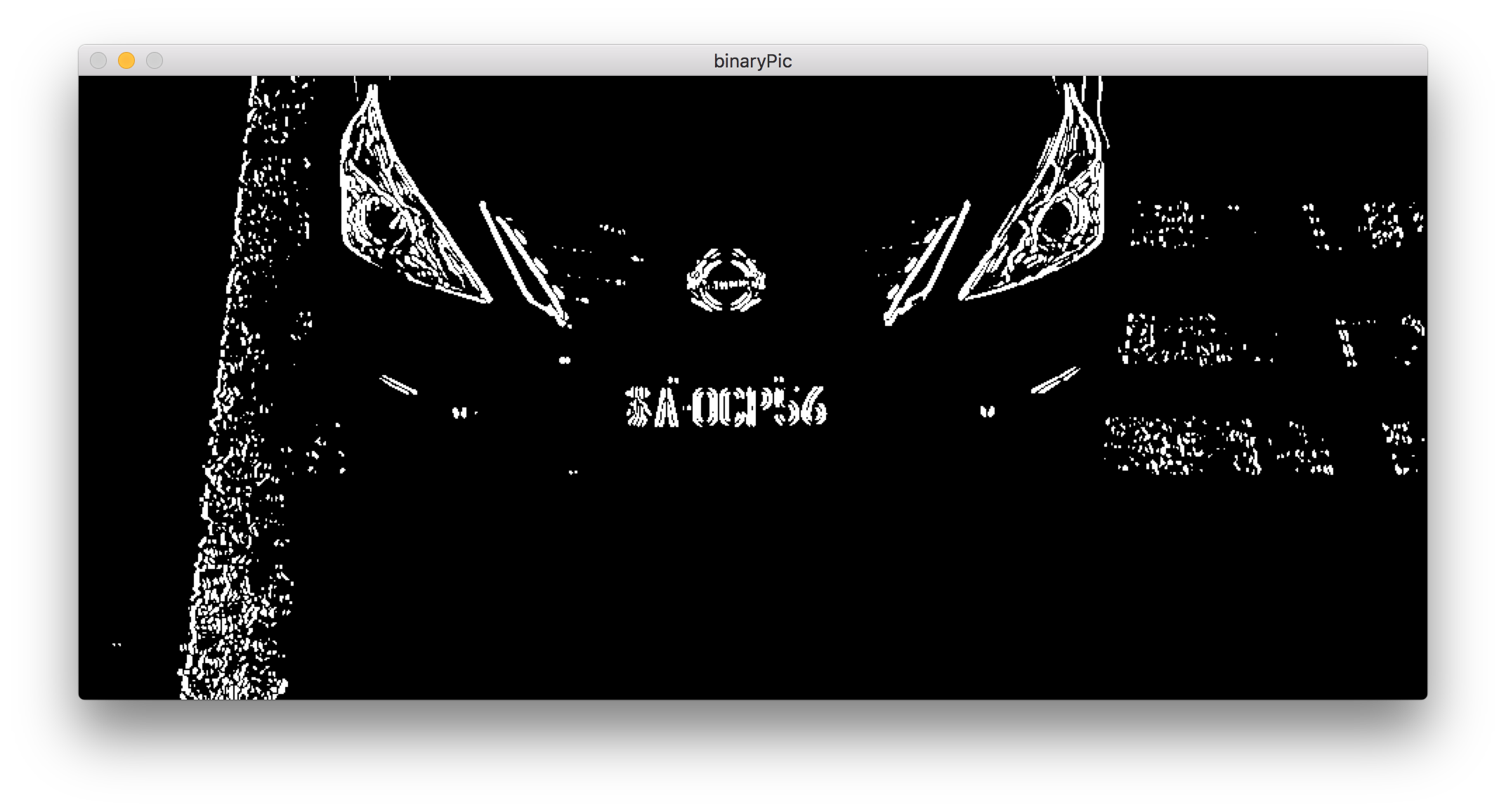
二值化
二值化算法非常简单,就是对图像的每个像素做一个阈值处理。
实现如下:
threshold(dst, img_threshold, 0, 255, CV_THRESH_OTSU+CV_THRESH_BINARY);
CV_THRESH_OTSU代表自适应阈值,CV_THRESH_BINARY代表正二值化
闭操作
将车牌字母连接成为一个连通域,便于取轮廓。
闭操作就是对图像先膨胀,再腐蚀。闭操作的结果一般是可以将许多靠近的图块相连称为一个无突起的连通域。在我们的图像定位中,使用了闭操作去连接所有的字符小图块,然后形成一个车牌的大致轮廓。闭操作的过程我会讲的细致一点。为了说明字符图块连接的过程。在这里选取的原图跟上面三个操作的原图不大一样,是一个由两个分开的图块组成的图。原图首先经过膨胀操作,将两个分开的图块结合起来(注意我用偏白的灰色图块表示由于膨胀操作而产生的新的白色)。接着通过腐蚀操作,将连通域的边缘和突起进行削平(注意我用偏黑的灰色图块表示由于腐蚀被侵蚀成黑色图块)。最后得到的是一个无突起的连通域(纯白的部分)。
在opencv中,调用闭操作的方法是首先建立矩形模板,矩形的大小是可以设置的,由于矩形是用来覆盖以中心像素的所有其他像素,因此矩形的宽和高最好是奇数
Mat element = getStructuringElement(MORPH_RECT, Size(getM_MorphSizeWidth(), getM_MorphSizeHeight()) );
morphologyEx(img_threshold, img_threshold, MORPH_CLOSE, element);
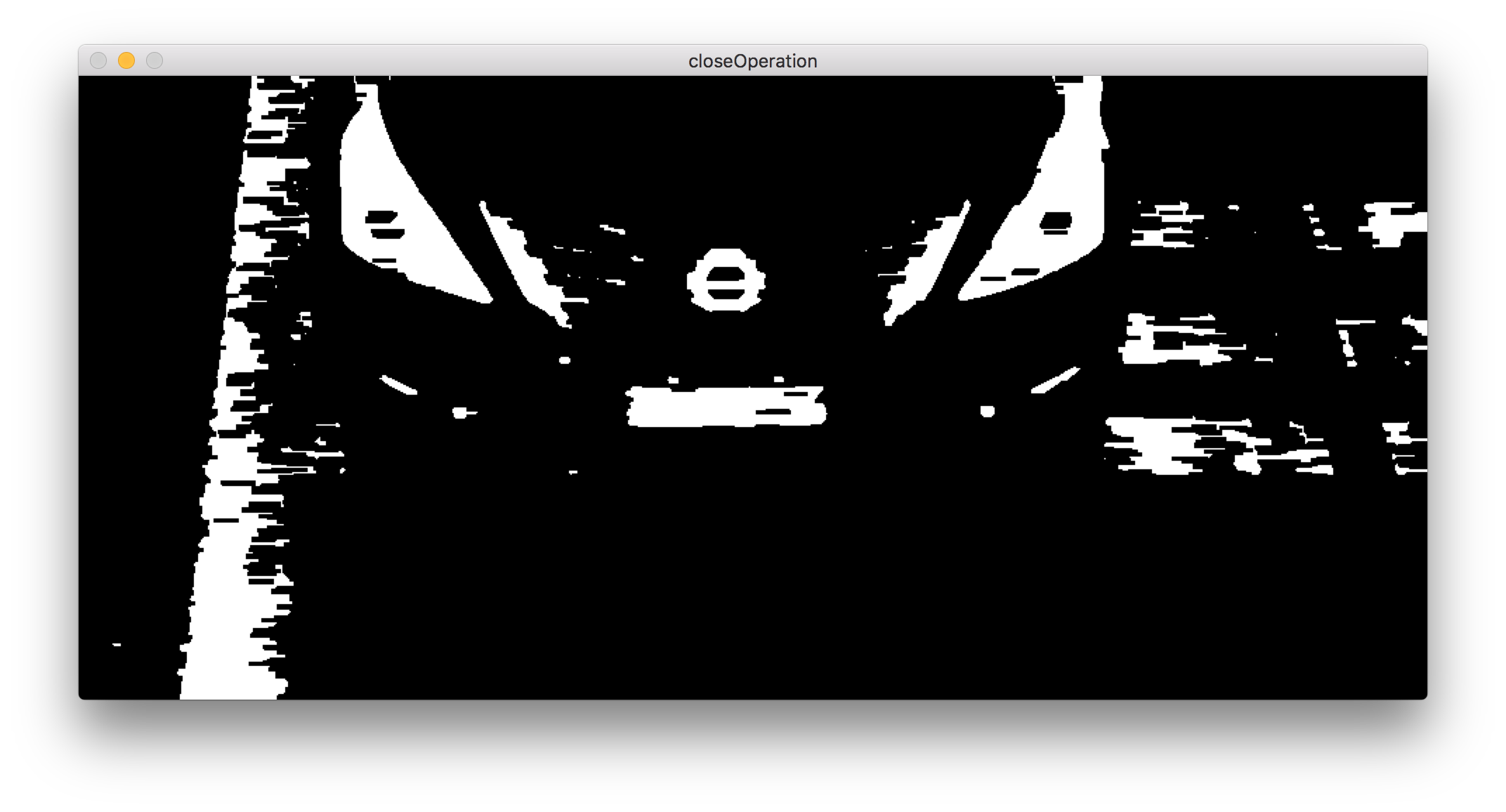
可以看出,使用闭操作以后,车牌字符的图块被连接成了一个较为规则的矩形,通过闭操作,将车牌中的字符连成了一个图块,同时将突出的部分进行裁剪,图块成为了一个类似于矩形的不规则图块。我们知道,车牌应该是一个规则的矩形,因此获取规则矩形的办法就是先取轮廓,再接着求最小外接矩形。
取轮廓
将连通域的外围勾画出来,便于形成外接矩形。
vector< vector< Point> > contours;
findContours(img_threshold, contours, // a vector of contours
CV_RETR_EXTERNAL, // 提取外部轮廓
CV_CHAIN_APPROX_NONE); // all pixels of each contours
Mat result;
src.copyTo(result);
drawContours(result, contours,
-1, // draw all contours
Scalar(0,0,255), // in blue
1); // with a thickness of

在图中,红色的线条就是轮廓,可以看到,有非常多的轮廓。取轮廓操作就是将图像中的所有独立的不与外界有交接的图块取出来。然后根据这些轮廓,求这些轮廓的最小外接矩形。这里面需要注意的是这里用的矩形是RotatedRect,意思是可旋转的。因此我们得到的矩形不是水平的,这样就为处理倾斜的车牌打下了基础。
尺寸判断
尺寸判断操作是对外接矩形进行判断,以判断它们是否是可能的候选车牌的操作。
排除不可能是车牌的矩形。 经过尺寸判断,会排除大量由轮廓生成的不合适尺寸的最小外接矩形.
中国车牌的一般大小是440mm140mm,面积为440140,宽高比为3.14。verifySizes使用如下方法判断矩形是否是车牌:
1.设立一个偏差率error,根据这个偏差率计算最大和最小的宽高比rmax、rmin。判断矩形的r是否满足在rmax、rmin之间。
2.设定一个面积最大值max与面积最小值min。判断矩形的面积area是否满足在max与min之间。
以上两个条件必须同时满足,任何一个不满足都代表这不是车牌。
偏差率和面积最大值、最小值都可以通过参数设置进行修改,且他们都有一个默认值。如果发现verifySizes方法无法发现你图中的车牌,试着修改这些参数。
另外,verifySizes方法是可选的。你也可以不进行verifySizes直接处理,但是这会大大加重后面的车牌判断的压力。一般来说,合理的verifySizes能够去除90%不合适的矩形。
通过对图像中所有的轮廓的外接矩形进行遍历,我们调用CplateLocate的另一个成员方法verifySizes,代码如下:
bool CPlateLocate::verifySizes(RotatedRect mr) {
float error = m_error;
//Spain car plate size: 52x11 aspect 4,7272
//China car plate size: 440mm*140mm,aspect 3.142857
float aspect = m_aspect;
//Set a min and max area. All other patchs are discarded
//int min= 1*aspect*1; // minimum area
//int max= 2000*aspect*2000; // maximum area
int min= 44*14*m_verifyMin; // minimum area
int max= 44*14*m_verifyMax; // maximum area
//Get only patchs that match to a respect ratio.
float rmin= aspect-aspect*error;
float rmax= aspect+aspect*error;
int area= mr.size.height * mr.size.width;
float r = (float)mr.size.width / (float)mr.size.height;
if(r < 1)
{
r= (float)mr.size.height / (float)mr.size.width;
}
if(( area < min || area > max ) || ( r < rmin || r > rmax ))
{
return false;
}
else
{
return true;
}
}

角度判断
角度判断操作通过角度进一步排除一部分车牌。
通过verifySizes的矩形,还必须进行一个筛选,即角度判断。一般来说,在一副图片中,车牌不太会有非常大的倾斜,我们做如下规定:如果一个矩形的偏斜角度大于某个角度(例如30度),则认为不是车牌并舍弃。
可以看出,原先的6个候选矩形只剩3个。车牌两侧的车灯的矩形被成功筛选出来。角度判断会去除verifySizes筛选余下的7%矩形,使得最终进入车牌判断环节的矩形只有原先的全部矩形的3%。
角度判断以及接下来的旋转操作的代码如下:
int k = 1;
for(int i=0; i< rects.size(); i++)
{
RotatedRect minRect = rects[i];
if(verifySizes(minRect))
{
// rotated rectangle drawing
// Get rotation matrix
// 旋转这部分代码确实可以将某些倾斜的车牌调整正,
// 但是它也会误将更多正的车牌搞成倾斜!所以综合考虑,还是不使用这段代码。
// 2014-08-14,由于新到的一批图片中发现有很多车牌是倾斜的,因此决定再次尝试
// 这段代码。
if(m_debug)
{
Point2f rect_points[4];
minRect.points( rect_points );
for( int j = 0; j < 4; j++ )
line( result, rect_points[j], rect_points[(j+1)%4], Scalar(0,255,255), 1, 8 );
}
float r = (float)minRect.size.width / (float)minRect.size.height;
float angle = minRect.angle;
Size rect_size = minRect.size;
if (r < 1)
{
angle = 90 + angle;
swap(rect_size.width, rect_size.height);
}
//如果抓取的方块旋转超过m_angle角度,则不是车牌,放弃处理
if (angle - m_angle < 0 && angle + m_angle > 0)
{
//Create and rotate image
Mat rotmat = getRotationMatrix2D(minRect.center, angle, 1);
Mat img_rotated;
warpAffine(src, img_rotated, rotmat, src.size(), CV_INTER_CUBIC);
Mat resultMat;
resultMat = showResultMat(img_rotated, rect_size, minRect.center, k++);
resultVec.push_back(resultMat);
}
}
旋转
旋转操作是为后面的车牌判断与字符识别提高成功率的关键环节。
旋转操作将偏斜的车牌调整为水平。
使用旋转与不适用旋转的效果区别如下图:

可以看出,没有旋转操作的车牌是倾斜,加大了后续车牌判断与字符识别的难度。因此最好需要对车牌进行旋转。
在角度判定阈值内的车牌矩形,我们会根据它偏转的角度进行一个旋转,保证最后得到的矩形是水平的。调用的opencv函数如下
Mat rotmat = getRotationMatrix2D(minRect.center, angle, 1);
Mat img_rotated;
warpAffine(src, img_rotated, rotmat, src.size(), CV_INTER_CUBIC);
大小调整
结束了么?不,还没有,至少在我们把这些候选车牌导入机器学习模型之前,需要确保他们的尺寸一致。
机器学习模型在预测的时候,是通过模型输入的特征来判断的。我们的车牌判断模型的特征是所有的像素的值组成的矩阵。因此,如果候选车牌的尺寸不一致,就无法被机器学习模型处理。因此需要用resize方法进行调整。
我们将车牌resize为宽度136,高度36的矩形。为什么用这个值?这个值一开始也不是确定的,我试过许多值。最后我将近千张候选车牌做了一个统计,取它们的平均宽度与高度,因此就有了136和36这个值。所以,这个是一个统计值,平均来说,这个值的效果最好。
大小调整调用了CplateLocate的最后一个成员方法showResultMat
//! 显示最终生成的车牌图像,便于判断是否成功进行了旋转。
Mat CPlateLocate::showResultMat(Mat src, Size rect_size, Point2f center, int index)
{
Mat img_crop;
getRectSubPix(src, rect_size, center, img_crop);
if(m_debug)
{
stringstream ss(stringstream::in | stringstream::out);
ss << "tmp/debug_crop_" << index << ".jpg";
imwrite(ss.str(), img_crop);
}
Mat resultResized;
resultResized.create(HEIGHT, WIDTH, TYPE);
resize(img_crop, resultResized, resultResized.size(), 0, 0, INTER_CUBIC);
if(m_debug)
{
stringstream ss(stringstream::in | stringstream::out);
ss << "tmp/debug_resize_" << index << ".jpg";
imwrite(ss.str(), resultResized);
}
return resultResized;
}
总结
通过接近10多个步骤的处理,我们才有了最终的候选车牌。这些过程是一环套一环的,前步骤的输出是后步骤的输入,而且顺序也是有规则的。目前针对我的测试图片来说,它们工作的很好,但不一定适用于你的情况。车牌定位以及图像处理算法的一个大的问题就是他的弱鲁棒性,换一个场景可能就得换一套工作方式。因此结合你的使用场景来做调整吧.