聚类是一种非监督学习方法
在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正 样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签,我们需要据此拟合一 个假设函数。与此不同的是,在非监督学习中,我们的数据没有附带任何标签,我们拿到的 数据就是这样的:
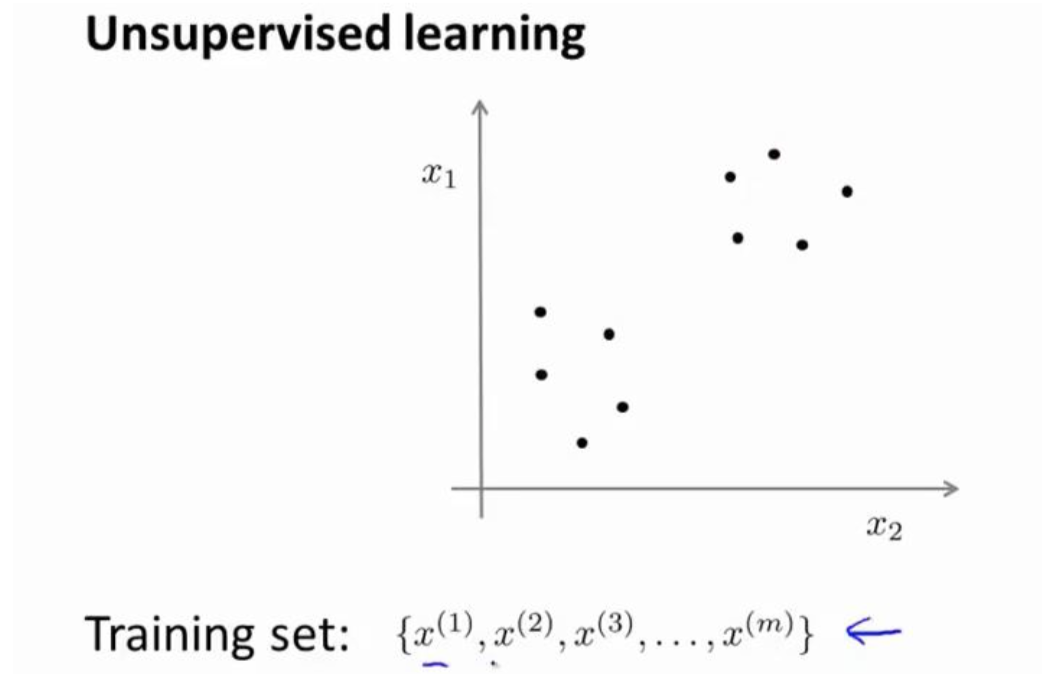
在这里我们有一系列点,却没有标签。因此,我们的训练集可以写成只有 x(1),x(2)…..一直 到 x(m)。我们没有任何标签 y。因此,图上画的这些点没有标签信息。也就是说,在非监督 学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法, 快去为我们找找这个数据的内在结构给定数据。我们可能需要某种算法帮助我们寻找一种结 构。图上的数据看起来可以分成两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
K-均值算法
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的 组。
K-均值是一个迭代算法,假设我们想要将数据聚类成 n 个组,其方法为:
- 首先选择 K 个随机的点,称为聚类中心(cluster centroids);
- 对于数据集中的每一个数据,按照距离 K 个中心点的距离,将其与距离最近的中心点关 联起来,与同一个中心点关联的所有点聚成一类。
- 计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置。
- 重复步骤 2-4 直至中心点不再变化。

算法分为两个步骤,第一个 for 循环是赋值步骤,即:对于每一个样例 i,计算其应该属 于的类。第二个 for 循环是聚类中心的移动,即:对于每一个类 k,重新计算该类的质心。
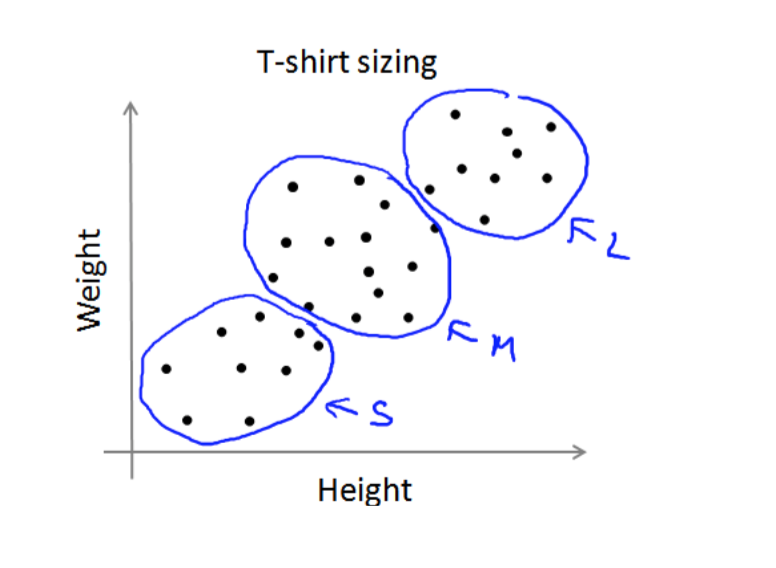
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组 群的情况下也可以。下图所示的数据集包含身高和体重两项特征构成的,利用 K-均值算法将
数据分为三类,用于帮助确定将要生产的 T-恤衫的三种尺寸。
优化目标
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和, 因此 K-均值的代价函数(又称畸变函数 Distortion function)为:

随机初始化
在运行 K-均值算法的之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样 做:
- 我们应该选择 K<m,即聚类中心点的个数要小于所有训练集实例的数量
- 随机选择 K 个训练实例,然后令 K 个聚类中心分别与这 K 个训练实例相等
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情 况。
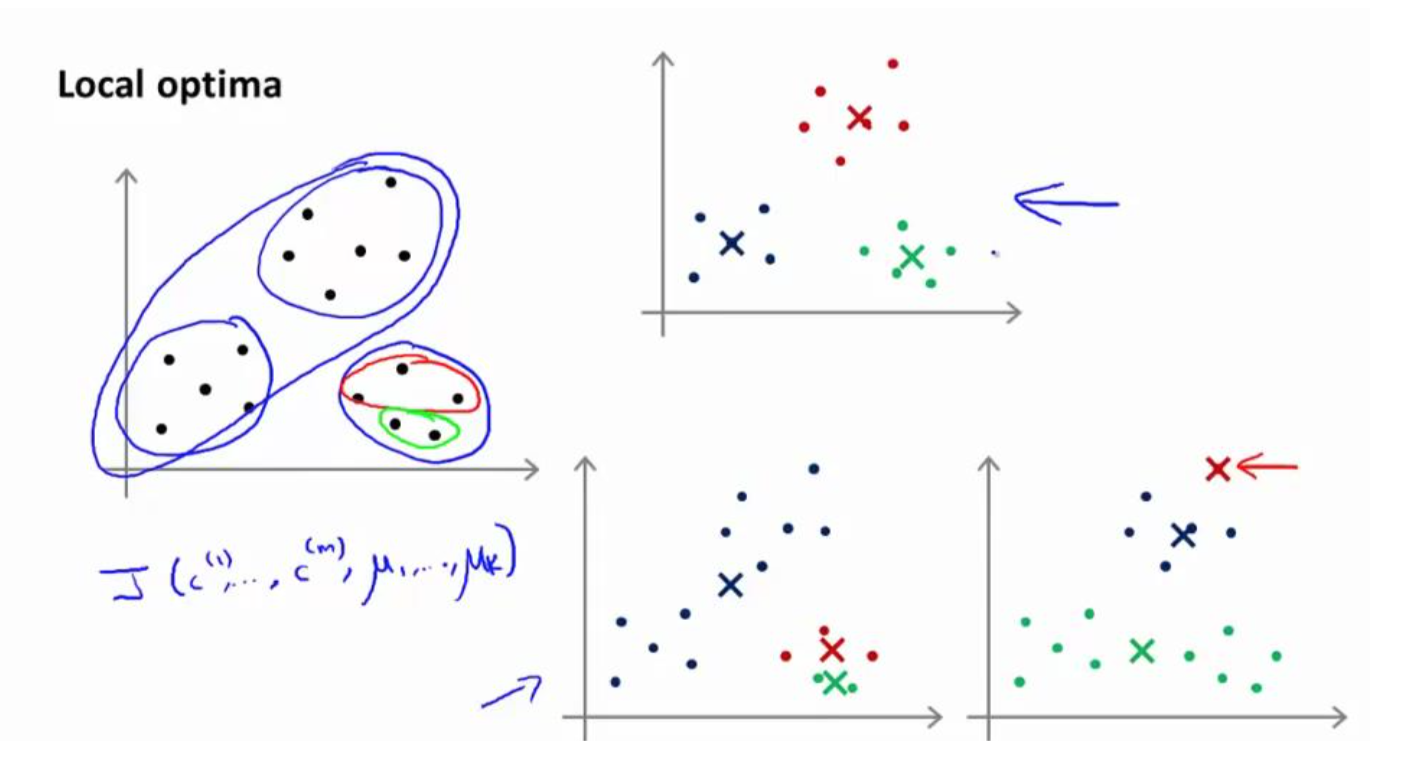
为了解决这个问题,我们通常需要多次运行 K-均值算法,每一次都重新进行随机初始 化,最后再比较多次运行 K-均值的结果,选择代价函数最小的结果。这种方法在 K 较小的时 候(2–10)还是可行的,但是如果 K 较大,这么做也可能不会有明显地改善。
选择聚类数
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。选
择的时候思考我们运用 K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚 类数。
当人们在讨论,选择聚类数目的方法时,有一个可能会谈及的方法叫作“肘部法则”。 关于“肘部法则”,我们所需要做的是改变 K 值,也就是聚类类别数目的总数。我们用一个 聚类来运行 K 均值聚类方法。这就意味着,所有的数据都会分到一个聚类里,然后计算成本 函数或者计算畸变函数 J。K 代表聚类数字。
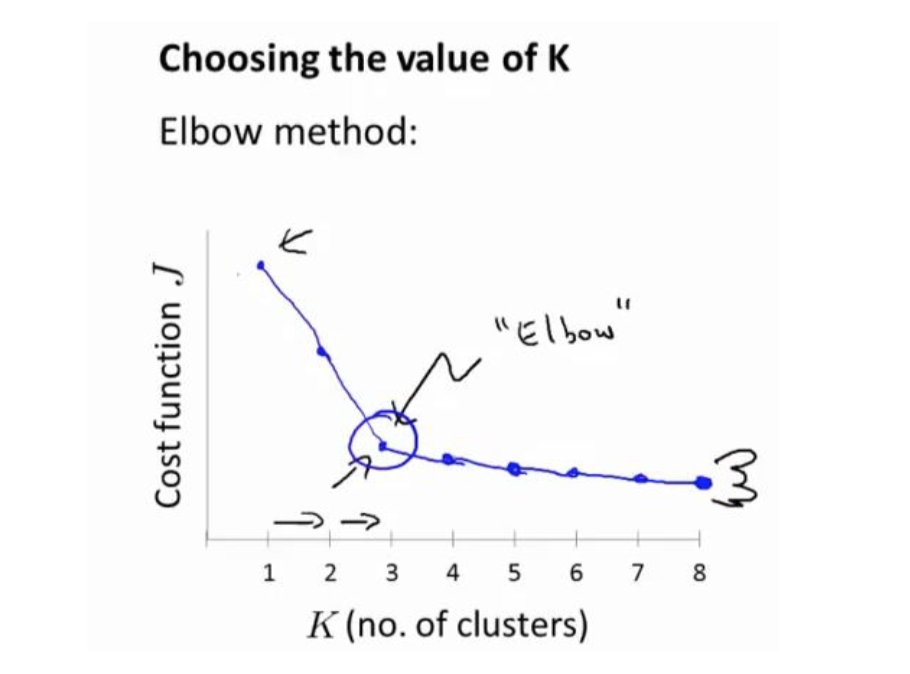
我们可能会得到一条类似于这样的曲线。像一个人的肘部。这就是“肘部法则”所做的, 让我们来看这样一个图,看起来就好像有一个很清楚的肘在那儿。好像人的手臂,如果你伸 出你的胳膊,那么这就是你的肩关节、肘关节、手。这就是“肘部法则”。你会发现这种模 式,它的畸变值会迅速下降,从 1 到 2,从 2 到 3 之后,你会在 3 的时候达到一个肘点。在 此之后,畸变值就下降的非常慢,看起来就像使用 3 个聚类来进行聚类是正确的,这是因为 那个点是曲线的肘点,畸变值下降得很快,K 等于 3 之后就下降得很慢,那么我们就选 K 等 于 3。当你应用“肘部法则”的时候,如果你得到了一个像上面这样的图,那么这将是一种 用来选择聚类个数的合理方法。
但也有可能不会有很明显的结果,只是平缓的下降,这样肘部法则就失效了。
我们也可以通过商业上的考虑来决定分类数
例如,我们的 T-恤制造例子中,我们要将用户按照身材聚类,我们可以分成 3 个尺寸 S,M,L 也可以分成 5 个尺寸 XS,S,M,L,XL,这样的选择是建立在回答“聚类后我们制造的 T-恤 是否能较好地适合我们的客户”这个问题的基础上作出的。
实现
function idx = findClosestCentroids(X, centroids)
% Set K
K = size(centroids, 1);
% You need to return the following variables correctly.
idx = zeros(size(X,1), 1);
for i=1:length(idx)
distanse = pdist2(centroids,X(i,:)); % compute the distance(K,1) pdist2 is a good function
[C,idx(i)]=min(distanse); % find the minimum
end
end
计算平均值,求得新的中心点
function centroids = computeCentroids(X, idx, K)
for i=1:K
centroids(i,:) = mean( X( find(idx==i) , :) ); %
end
end