知乎的反爬虫机制越来越严了,一不小心就被封号,只好使用代理IP,延长休息时间,好不容易爬了4000多条数据,到现在还是被封的。
爬虫主要注意以下内容
- 使用session模拟登陆
- 爬取策略,爬取每一个人的关注的人作为我们下一次爬取的目标
- 使用requests访问,用cokie模拟登陆
- 使用lxml,xpath解析页面
- 使用mongodb存储数据
- 使用redis做为任务队列
crawler.py
import requests
from lxml import html
from db import Zhihu_User_Profile
from red_filter import check_url, re_crawl_url
import random
import time
from bs4 import BeautifulSoup
class SpiderProxy(object):
"""黄哥Python培训 黄哥所写 Python版本为2.7以上"""
headers = {
"Host": "www.xicidaili.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:47.0) Gecko/20100101 Firefox/47.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://www.xicidaili.com/wt/1",
}
def __init__(self, session_url):
self.req = requests.session()
self.req.get(session_url)
def get_pagesource(self, url):
html = self.req.get(url, headers=self.headers)
return html.content
def get_all_proxy(self, url, n):
data = []
for i in range(1, n):
html = self.get_pagesource(url + str(i))
soup = BeautifulSoup(html, "lxml")
table = soup.find('table', id="ip_list")
print(type(table))
for row in table.findAll("tr"):
cells = row.findAll("td")
tmp = []
for item in cells:
tmp.append(item.find(text=True))
data.append(tmp[1:3])
return data
class Zhihu_Crawler():
'''
basic crawler
'''
def __init__(self,url,option="print_data_out"):
'''
initialize the crawler
'''
self.option=option
self.url=url
self.header={}
self.header["User-Agent"]="Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:43.0) Gecko/20100101 Firefox/43.0"
# self.header["Host"]="www.zhihu.com"
self.header["Referer"]="www.zhihu.com"
#cookie
self.cookies={"q_c1":"a57da482190149c598ea41970ed39289|1472689490000|1472689490000",
"_xsrf":"bfdb84f58409e2f2b028b44a3e902d0b",
"d_c0":"AABAwkDceAqPTpwAGa9drbEiAVyxwnKIdLk=|1472689493",
" _zap":"56de3379-1be2-4fd4-8e32-e78e16c2d2e5",
"_za":"01619ad1-d465-4e22-89a4-8ac36b669864",
"a_t":'"2.0AADAlWcvAAAXAAAAB1vzVwAAwJVnLwAAAIDALVtgcQoXAAAAYQJVTdqD51cA5BWpP3Ia7DK9D31FNsVyKP043vAvISraCDclEqORCO9pgoL7d4uCQA=="',
"z_c0":"Mi4wQUFEQWxXY3ZBQUFBZ01BdFcyQnhDaGNBQUFCaEFsVk4yb1BuVndEa0Zha19jaHJzTXIwUGZVVTJ4WElvX1RqZThB|1472974343|dd5d7646eb4742626b9b40fd542bfc3dae0cb33b",
}
def send_request(self):
'''
send a request to get HTML source
'''
added_followee_url = self.url.decode("utf-8") + "/followees"
temp=random.randint(0,10)
if temp<5:
print("sleeping")
time.sleep(3)
session_url = 'http://www.xicidaili.com/wt/1'
url = 'http://www.xicidaili.com/wt/'
#p = SpiderProxy(session_url)
proxy_ip ={
"202.43.147.226",
"117.166.183.111",
"125.33.207.59",
"218.94.149.147",
"113.5.211.198",
"110.73.8.230",
"183.254.228.144",
"111.1.3.36",
"114.232.70.191",
"183.224.99.151",
"114.113.126.32"
}
try:
r = requests.get(added_followee_url, cookies=self.cookies, headers=self.header, verify=False)
except:
re_crawl_url(self.url)
print("here1")
return
content = r.text
#print(content)
if r.status_code == 200:
self.parse_user_profile(content)
def process_xpath_source(self, source):
if source:
#print(source[0])
return source[0]
else:
return ''
def parse_user_profile(self, html_source):
'''
parse the user's profile to mongo
'''
# initialize variances
self.user_name = ''
self.fuser_gender = ''
self.user_location = ''
self.user_followees = ''
self.user_followers = ''
self.user_be_agreed = ''
self.user_be_thanked = ''
self.user_education_school = ''
self.user_education_subject = ''
self.user_employment = ''
self.user_employment_extra = ''
self.user_info = ''
self.user_intro = ''
tree = html.fromstring(html_source)
# parse the html via lxml
self.user_name = self.process_xpath_source(tree.xpath("//a[@class='name']/text()"))
self.user_location = self.process_xpath_source(tree.xpath("//span[@class='location item']/@title"))
self.user_gender = self.process_xpath_source(tree.xpath("//span[@class='item gender']/i/@class"))
if "female" in self.user_gender and self.user_gender:
self.user_gender = "female"
else:
self.user_gender = "male"
self.user_employment = self.process_xpath_source(tree.xpath("//span[@class='employment item']/@title"))
self.user_employment_extra = self.process_xpath_source(tree.xpath("//span[@class='position item']/@title"))
self.user_education_school = self.process_xpath_source(tree.xpath("//span[@class='education item']/@title"))
self.user_education_subject = self.process_xpath_source(
tree.xpath("//span[@class='education-extra item']/@title"))
try:
self.user_followees = tree.xpath("//div[@class='zu-main-sidebar']//strong")[0].text
self.user_followers = tree.xpath("//div[@class='zu-main-sidebar']//strong")[1].text
except:
return
self.user_be_agreed = self.process_xpath_source(
tree.xpath("//span[@class='zm-profile-header-user-agree']/strong/text()"))
self.user_be_thanked = self.process_xpath_source(
tree.xpath("//span[@class='zm-profile-header-user-thanks']/strong/text()"))
self.user_info = self.process_xpath_source(tree.xpath("//span[@class='bio']/@title"))
self.user_intro = self.process_xpath_source(tree.xpath("//span[@class='content']/text()"))
if self.option == "print_data_out":
self.print_data_out()
else:
self.store_data_to_mongo()
# find the follower's url
#print("here2")
url_list = tree.xpath("//h2[@class='zm-list-content-title']/span/a/@href")
#print(url_list)
for target_url in url_list:
#print(target_url)
target_url = target_url.replace("https", "http")
check_url(target_url)
def print_data_out(self):
'''
print out the user data
'''
print("*" * 60)
print('用户名:%s\n' % self.user_name)
print("用户性别:%s\n" % self.user_gender)
print('用户地址:%s\n' % self.user_location)
print("被同意:%s\n" % self.user_be_agreed)
print("被感谢:%s\n" % self.user_be_thanked)
print("被关注:%s\n" % self.user_followers)
print("关注了:%s\n" % self.user_followees)
print("工作:%s/%s" % (self.user_employment, self.user_employment_extra))
print("教育:%s/%s" % (self.user_education_school, self.user_education_subject))
print("用户信息:%s" % self.user_info)
print("*" * 60)
def store_data_to_mongo(self):
'''
store the data in mongo
'''
new_profile = Zhihu_User_Profile(
user_name=self.user_name,
user_be_agreed=self.user_be_agreed,
user_be_thanked=self.user_be_thanked,
user_followees=self.user_followees,
user_followers=self.user_followers,
user_education_school=self.user_education_school,
user_education_subject=self.user_education_subject,
user_employment=self.user_employment,
user_employment_extra=self.user_employment_extra,
user_location=self.user_location,
user_gender=self.user_gender,
user_info=self.user_info,
user_intro=self.user_intro,
user_url=self.url
)
new_profile.save()
print("saved:%s \n" % self.user_name)
多进程和携程爬取
import gevent.monkey
gevent.monkey.patch_all()
import sys
import gevent
import redis
import crawler
import time
from multiprocessing.dummy import Pool
import multiprocessing
from red_filter import red, red_queue
#red_queue="test_the_url_queue"
#red_crawled_set="test_url_has_crawled"
process_pool=Pool(multiprocessing.cpu_count()*2)
#connect to redis server
#wrap the class method
def create_new_slave(url,option):
new_slave=crawler.Zhihu_Crawler(url,option)
new_slave.send_request()
return "ok"
def gevent_worker(option):
while True:
url=red.lpop(red_queue)
if not url:
break
create_new_slave(url,option)
def process_worker(option):
jobs=[]
for i in range(2):
jobs.append(gevent.spawn(gevent_worker,option))
gevent.joinall()
if __name__=="__main__":
'''
start the crawler
'''
start=time.time()
count=0
#choose the running way of using database or not
try:
option=sys.argv[1]
except:
option=''
if "mongo" not in option:
option="print_data_out"
#the start page
red.lpush(red_queue,"https://www.zhihu.com/people/mo-ming-42-91")
url=red.lpop(red_queue)
create_new_slave(url,option=option)
for i in range(2):
gevent_worker(option=option)
process_pool.map_async(process_worker,option)
process_pool.close()
process_pool.join()
print("crawler has crawled %d people ,it cost %s" % (count,time.time()-start))
数据分析
我们先从大学用户数据开始看起:
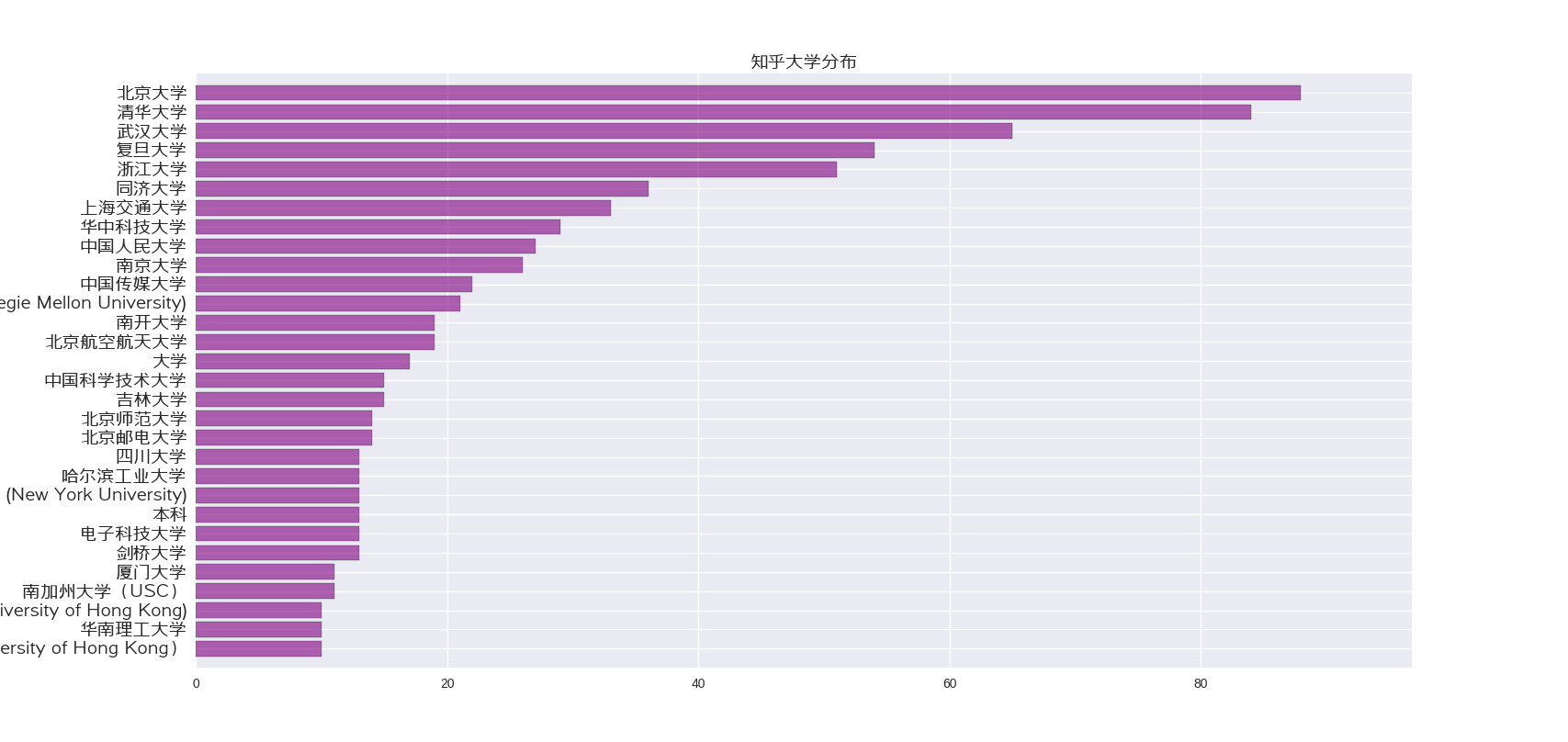
我们可以看到:
- 清北和武汉大学雄踞前三个,武汉大学多可能因为我关注的武大的比较多的原因。
- 接着,很明显前面的大学都是综合性大学,说明越是有多的文科专业的越有知乎上的求知欲
接着,我们看看知乎上面女性大学分布
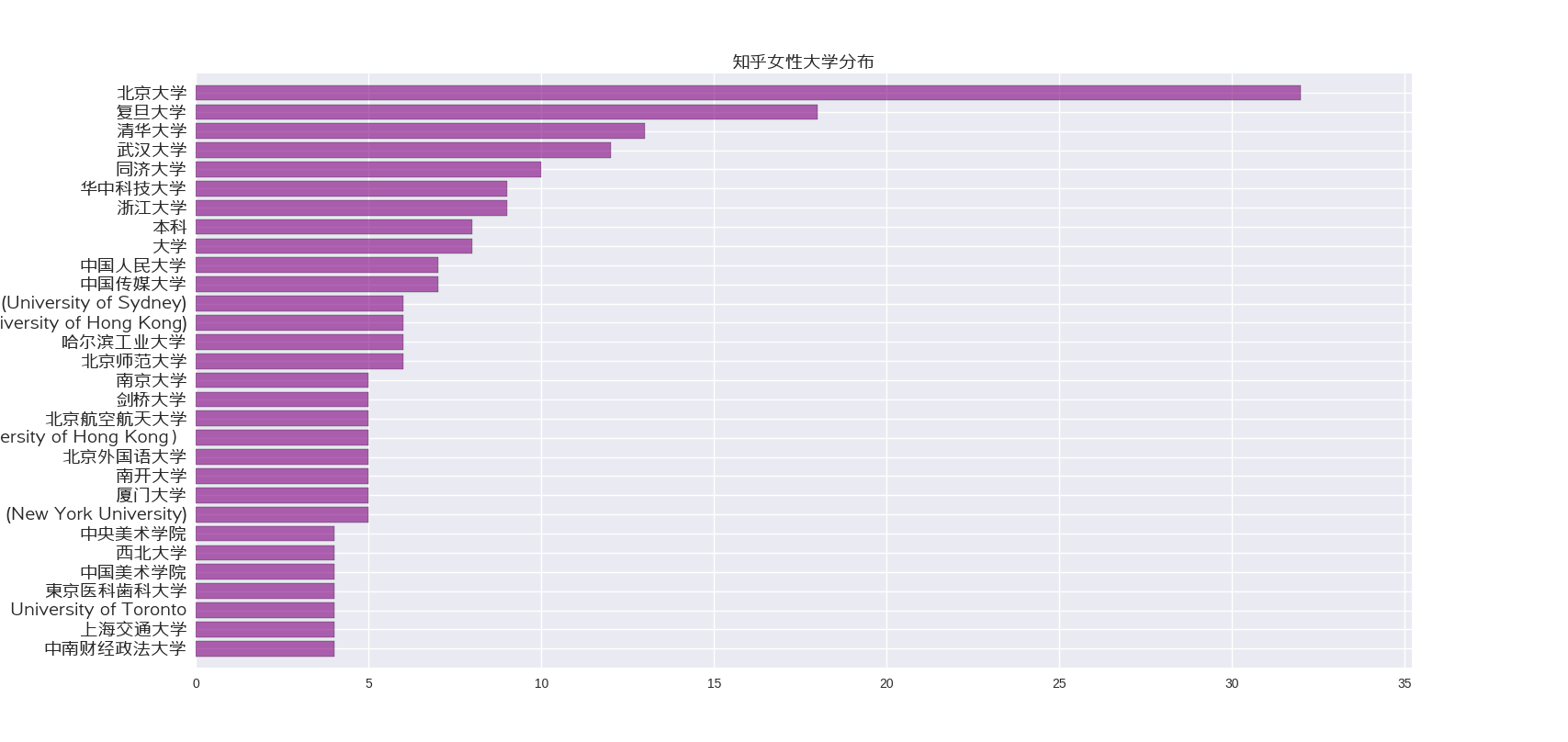
华科的女生为什么那么多,看来数据量还是太小了,不具有代表性
接下来,可以看一看北京大学专业分布
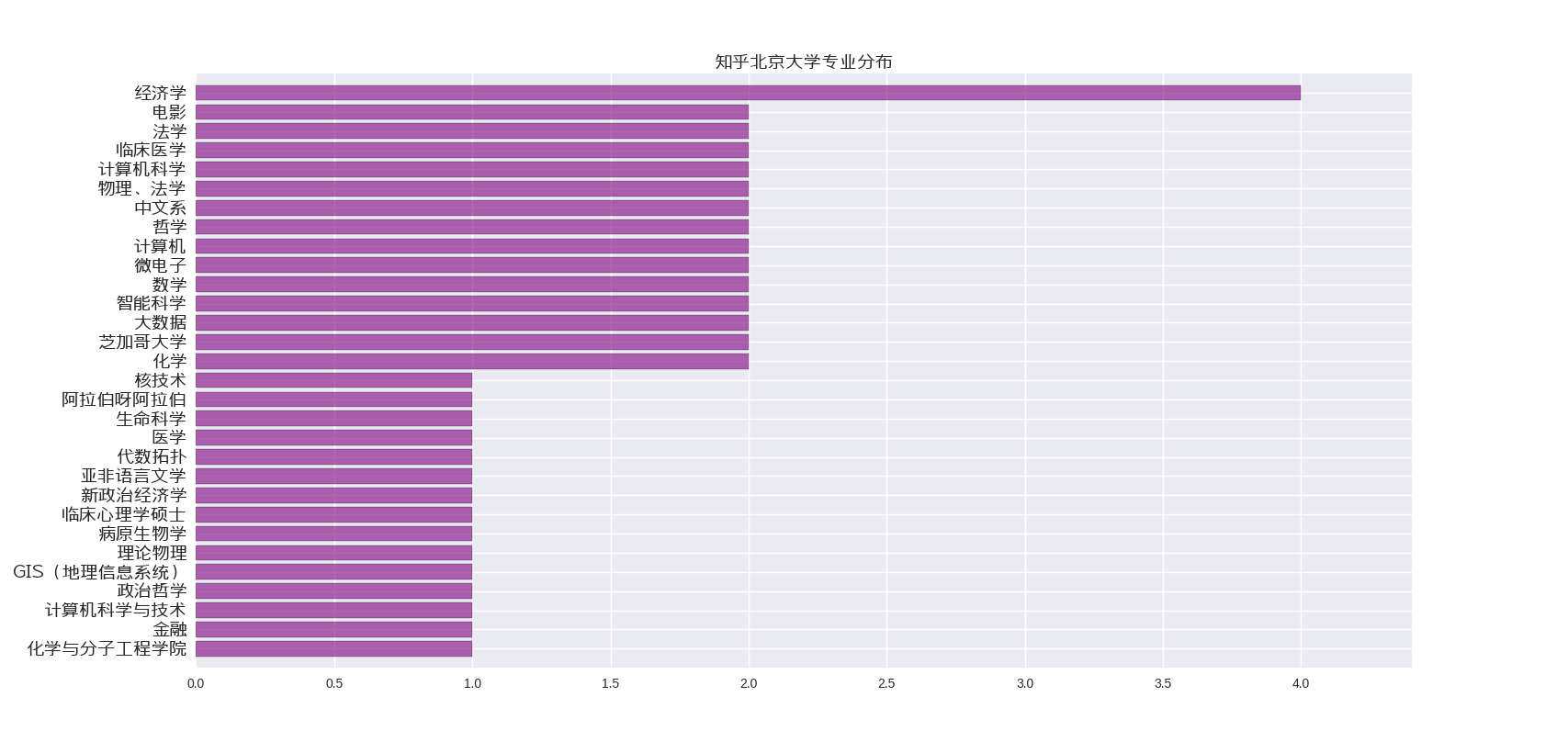
看来经济类专业的人最喜欢上知乎,遥遥领先
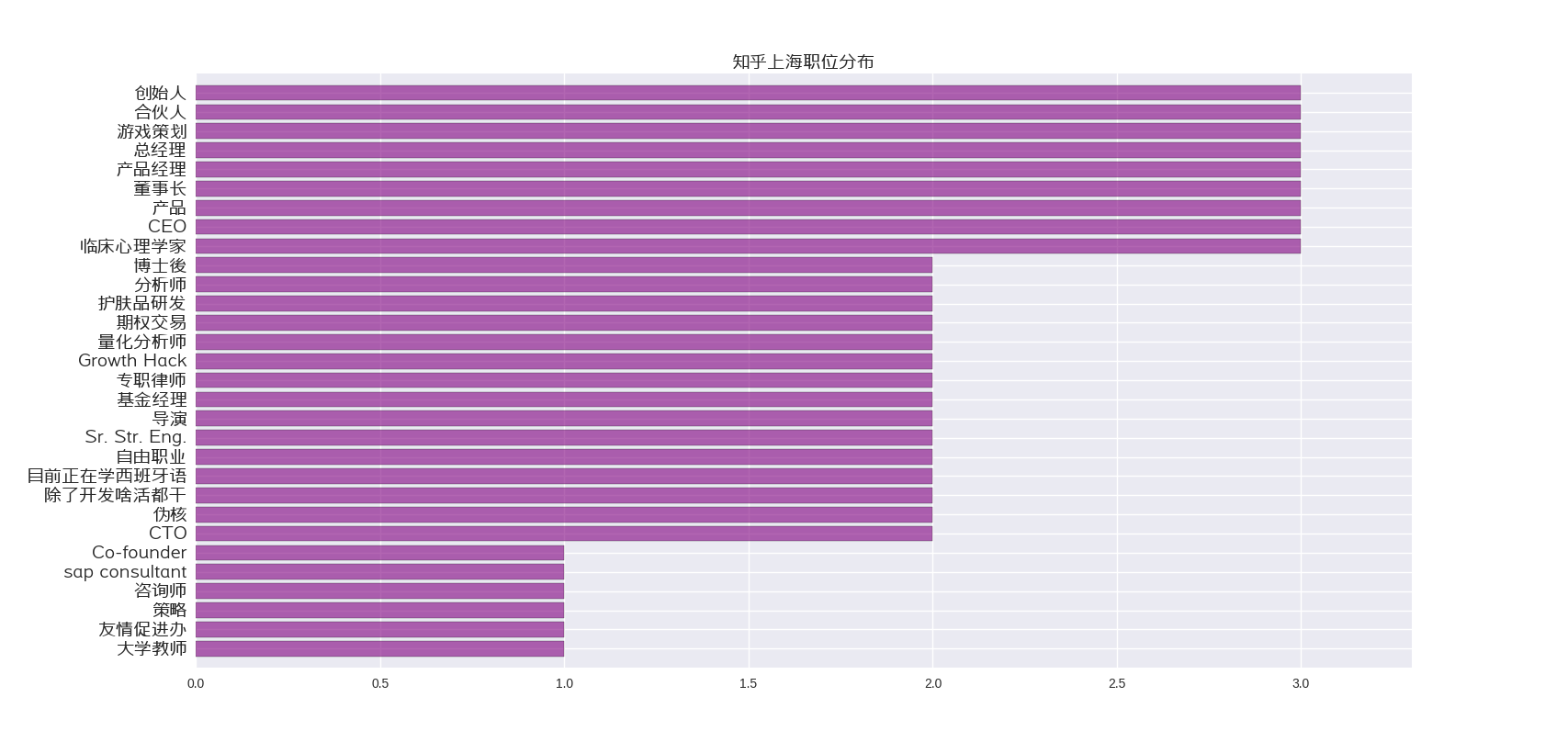
知乎公司分布,可能有点不太准确
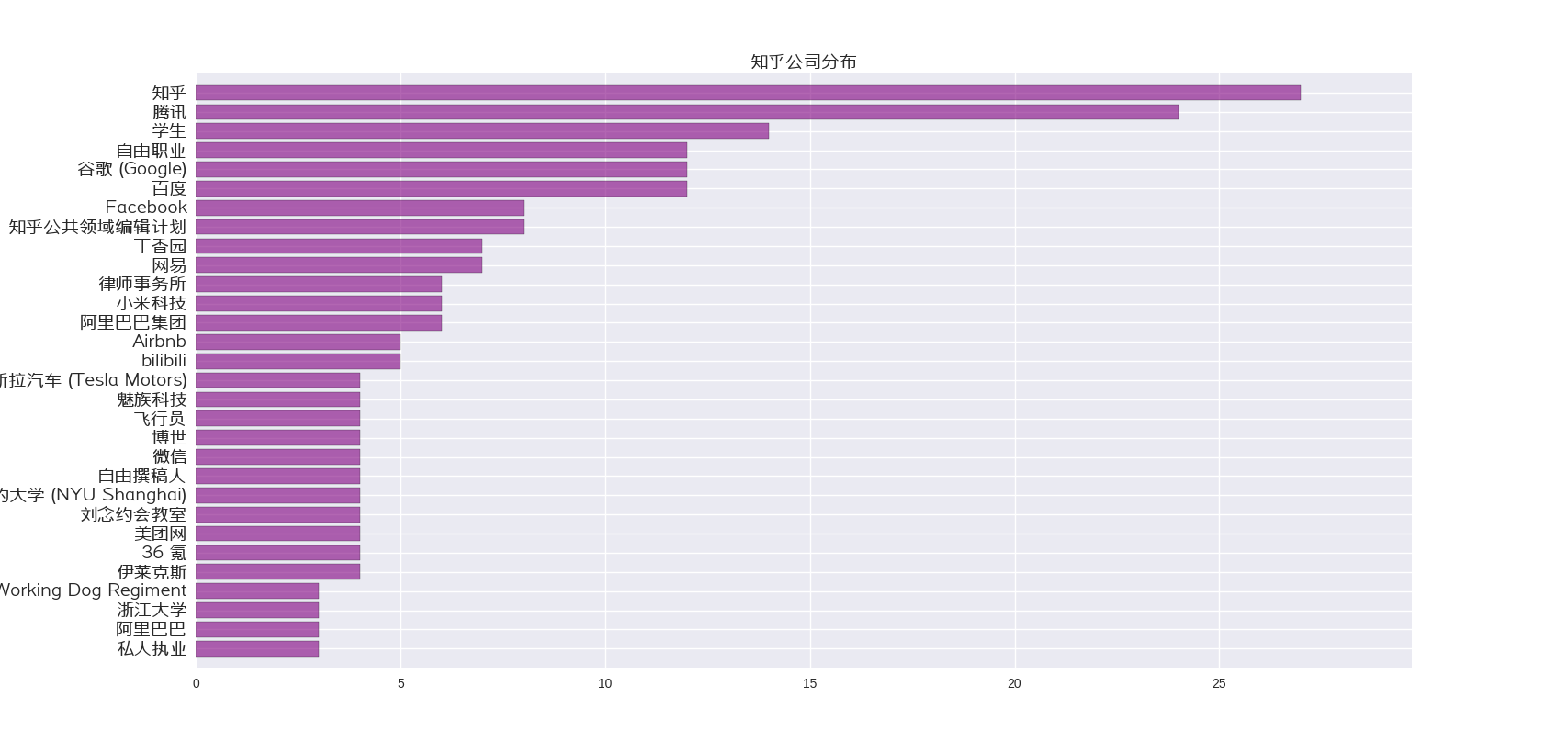
用户关系
被关注数(粉丝数)分布:
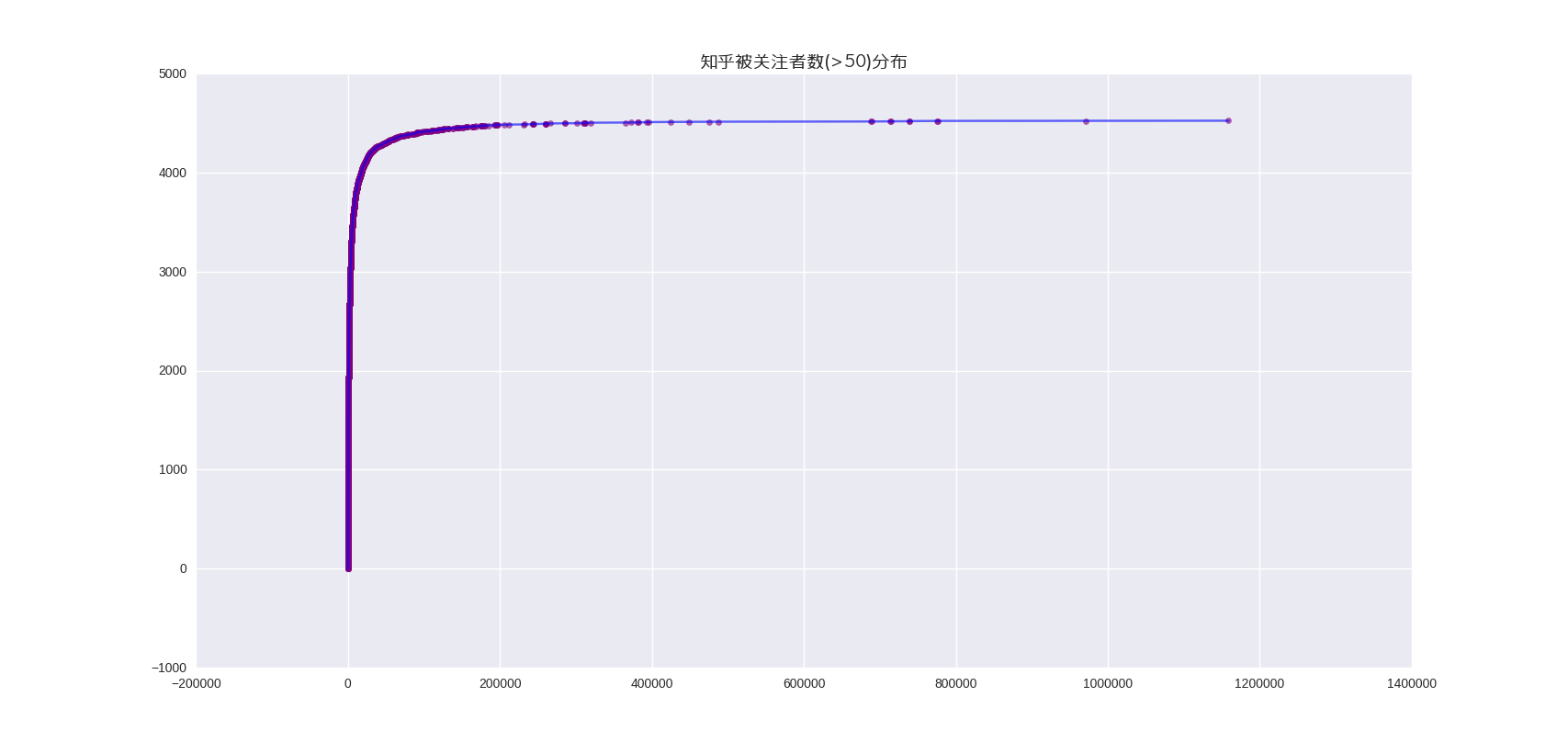
所以可以看到,知乎是一堆大v带着玩的社区
还有的就是知乎的性别分布了,居然不是1:1!!!!!!
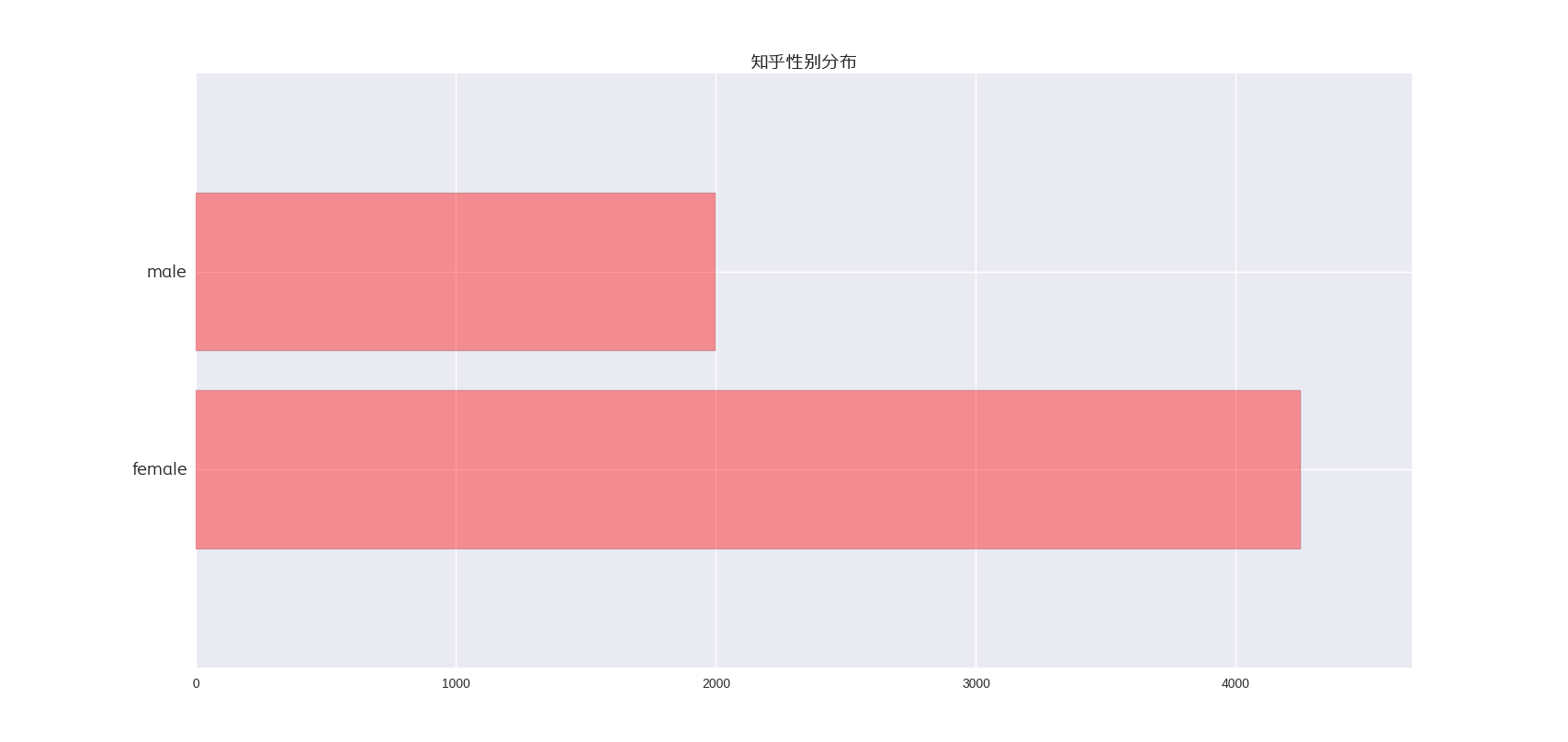
这个可能是因为我关注了轮子哥的缘故
使用的脚本代码如下
# -*- coding: utf-8 -*-
# encoding:utf-8
import sys
#sys.setdefaultencoding("utf-8")
import pandas as pd
import matplotlib.pylab as plt
import seaborn as sns
import numpy as np
from matplotlib.font_manager import FontProperties
data = pd.read_csv("output.csv")
font=FontProperties(fname=r'/usr/share/fonts/truetype/字体管家扁黑体.ttf',size=14)
'''
sr=data['user_education_school'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎大学分布",fontproperties=font)
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,30)
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 ,fontproperties=font)
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr=data[data['user_gender']=='female']['user_education_school'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎女性大学分布",fontproperties=font)
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,30)
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 ,fontproperties=font)
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr=data[data['user_education_school']=='北京大学']['user_education_subject'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎北京大学专业分布",fontproperties=font)
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,30)
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 ,fontproperties=font)
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr=data['user_employment'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎公司分布",fontproperties=font)
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,30)
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0,fontproperties=font)
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
plt.plot(data[data['user_followers']>50]['user_followers'].order(),np.arange(len(data[data['user_followers']>50])),color='blue',alpha=0.6)
plt.scatter(data[data['user_followers']>50]['user_followers'].order(),np.arange(len(data[data['user_followers']>50])),color='purple',alpha=0.6)
plt.title("知乎被关注者数(>50)分布",fontproperties=font)
plt.show()
'''
sr=data['user_gender'].value_counts()
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎性别分布",fontproperties=font)
rects1 = ax.barh(range(len(sr.values)),sr.values, align = 'center',alpha=0.4,color="red")
ax.set_ylim(-1,2)
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 ,fontproperties=font)
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
sr=data[((data['专业']=='计算机科学')|(data['专业']=='软件工程')|(data['专业']=='计算机')|(data['专业']=='计算机科学与技术')|(data['专业']=='通信工程')|(data['专业']=='计算机科学与技术'))]['公司'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎计算机相关专业公司分布")
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,len(sr))
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 )
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr=data[((data['专业']=='金融')|(data['专业']=='经济学')|(data['专业']=='计算机')|(data['专业']=='金融学')|(data['专业']=='市场营销')|(data['专业']=='会计'))]['公司'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎金融相关专业公司分布")
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,len(sr))
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 )
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr=data[((data['专业']=='计算机科学')|(data['专业']=='软件工程')|(data['专业']=='计算机')|(data['专业']=='计算机科学与技术')|(data['专业']=='通信工程')|(data['专业']=='计算机科学与技术'))]['所在地'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎计算机相关专业所在地分布")
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,len(sr))
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 )
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr=data[((data['专业']=='金融')|(data['专业']=='经济学')|(data['专业']=='计算机')|(data['专业']=='金融学')|(data['专业']=='市场营销')|(data['专业']=='会计'))]['所在地'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎金融相关专业所在地分布")
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,len(sr))
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 )
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr=data[data['所在地']=='北京']['公司'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎北京公司分布")
rects1 = ax.barh(range(len(sr.values)),sr.values[::-1], align = 'center',alpha=0.6,color="purple")
ax.set_ylim(-1,len(sr))
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0 )
ax.set_xlim(0,max(sr.values)*1.1)
plt.show()
'''
'''
sr = data[data['user_location'] == '上海']['user_employment_extra'].value_counts()[:30]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("知乎上海职位分布",fontproperties=font)
rects1 = ax.barh(range(len(sr.values)), sr.values[::-1], align='center', alpha=0.6, color="purple")
ax.set_ylim(-1, len(sr))
ax.set_yticks(range(len(sr.values)))
ax.set_yticklabels(sr.index[::-1], rotation=0,fontproperties=font)
ax.set_xlim(0, max(sr.values) * 1.1)
plt.show()
'''
源代码:知乎爬虫
参考链接